¶ Danksharding P2P Network
¶ Prerequisites
¶ Time in Ethereum
Every 12 seconds, Ethereum opens a new slot, expecting a new block.
Within a block there are thousands transactions, but they execute atomically: either all together or none at all.
An epoch is made up of 32 slots.
¶ The World Computer
Ethereum exists between a network of 1,000s of computers (nodes), each running a local version of the Ethereum Virtual Machine (EVM). All copies of the EVM are kept perfectly in sync.
Any individual EVM is a window into the shared state of the World Computer.
Today, the World Computer is... just ok. Execution is expensive and there isn't that much storage space. Yes, you can do (almost) anything, it's just going to be expensive and slow.
The solution: rollups. Independent blockchains that use Ethereum as a settlement layer.
¶ The Data Availability Bottleneck
Deep Dive: Data Availability Bottleneck
Rollups are fantastic; we're barely in the opening inning and we've already seen just how fast and cheap we can get execution.
Unfortunately, rollups only solve the execution problem. If anything they actually make handling data even more of a challenge.
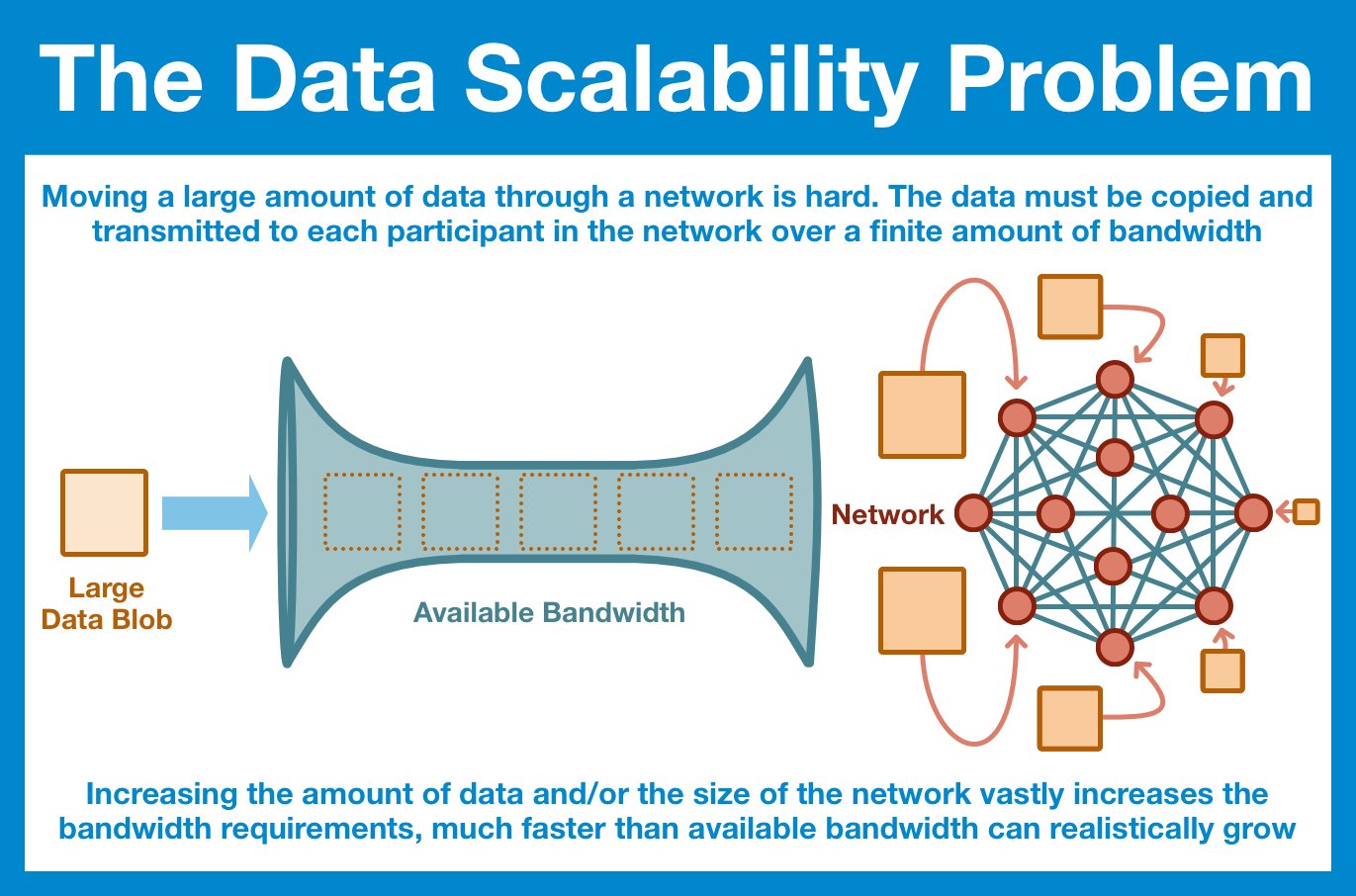
And so, this is the problem space we are entering: how can we scale the data capabilities of Ethereum without increasing the individual node requirements?
There really only is one option: we have to distribute the data.
¶ Ethereum Actors
Node - real computer running Ethereum software, can run many validators
Validator - a role granted by staking $ETH, requires operating a node
Ethereum itself doesn't distinguish; from the protocol's perspective, a validator = node = IRL computer
¶ Types of Networks
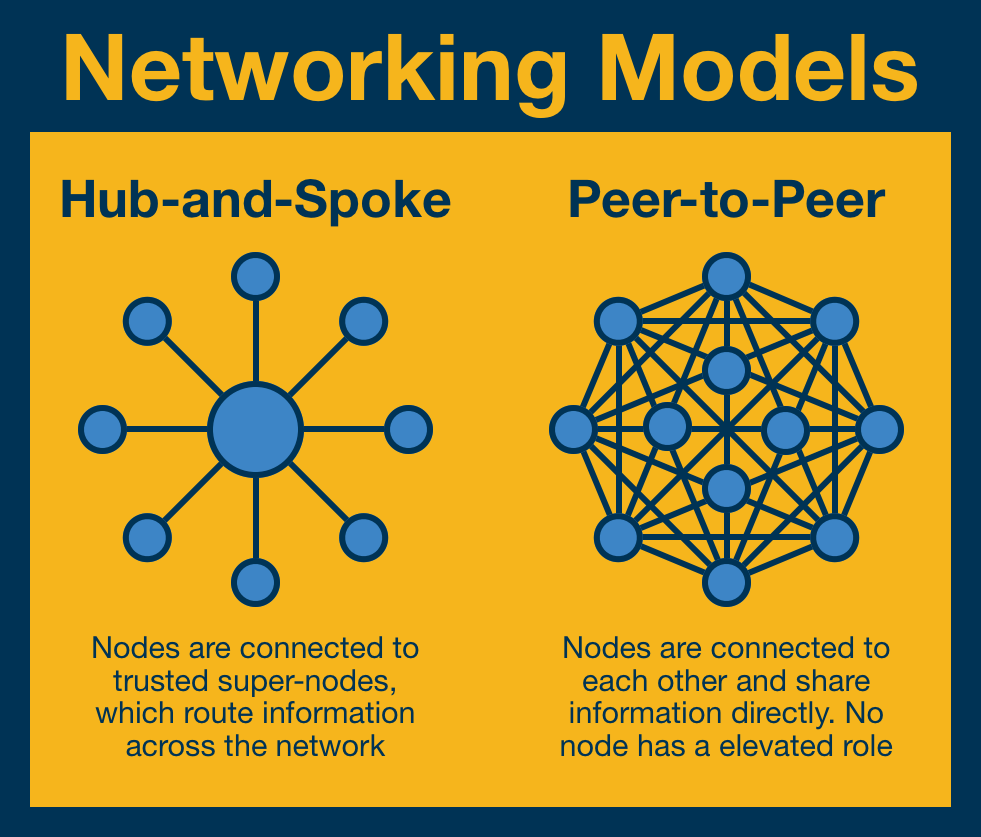
Let's consider two models of network: hub-and-spoke and peer-to-peer.
- Hub-and-spoke = centralized (trusted) super-nodes route traffic through the network.
- Peer-to-peer (P2P) = each node connects directly to its peer nodes. No node is more trusted than another.
Ethereum is an example of a P2P network: each validator has the same privileges and responsibilities as the other validators and send messages directly to their peer nodes.
The problem: there are ~450k validators, all chattering back and forth.
That is SO MUCH noise.
Fortunately, we have a solution: we can implement communication channels.
Remember those push-to-talk radios? Same idea, you can only send/receive messages from the channel you are currently tuned into.

¶ Distributing the Data
We are going to apply two separate strategies.
¶ Randomly Sampled Committees
Deep Dive: Randomly Sampled Committees
First, randomly sampled committees.
The validator set will be broken into committees, each responsible for ensuring data availability for only a single blob.
¶ Data Availability Sampling
Deep Dive: Data Availability Sampling
Second, we will apply data availability sampling.
Every validator engages in data availability sampling, selecting a tiny portion of the data across every block/blob and attempting to download it.
¶ P2P Network Design

Now we can begin to see our P2P Network design.
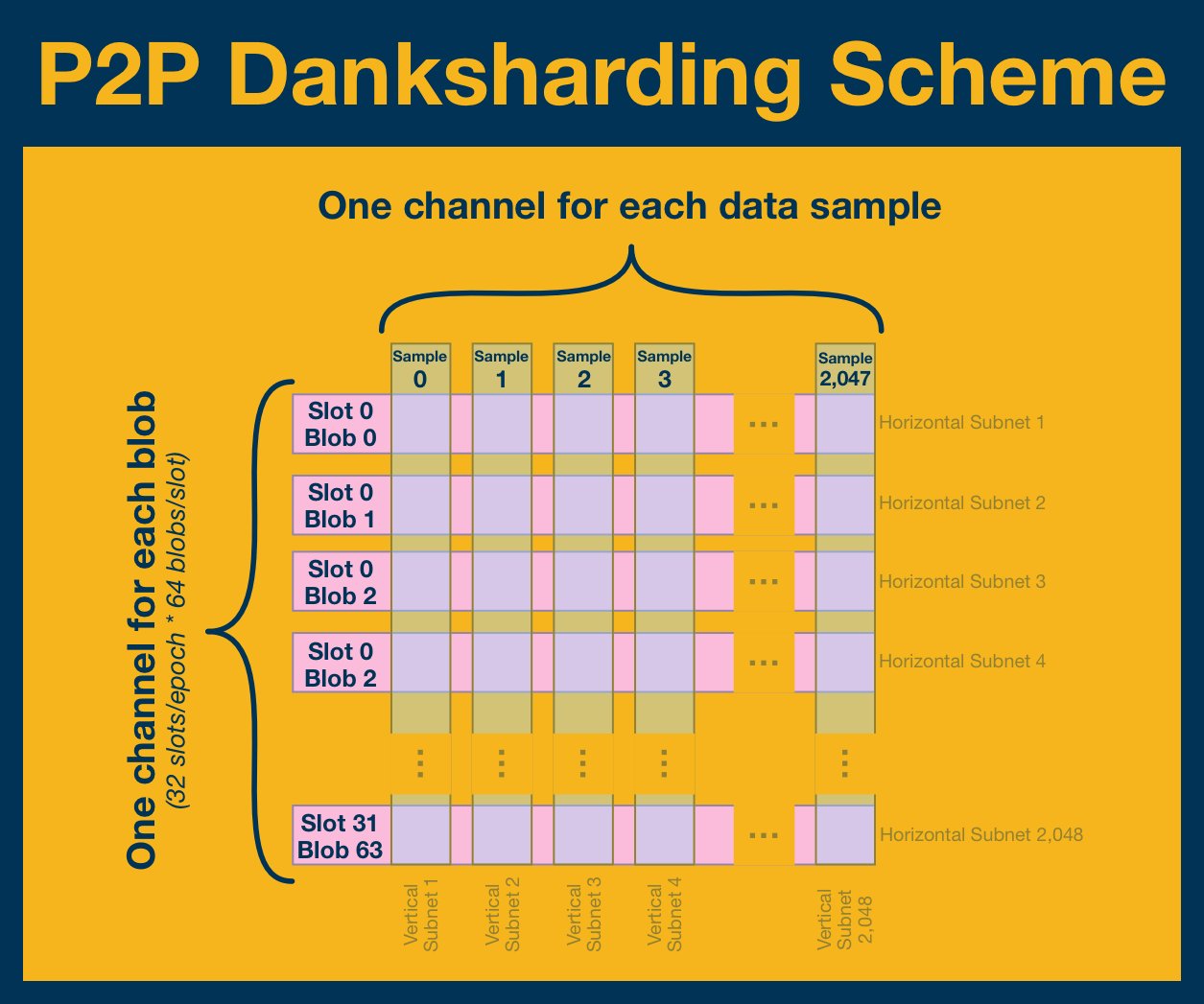
We start with our unit of time: epochs. We need channels for each blob and each index, implying a two-dimensional design.
And so, we'll build out a P2P grid!
Rows represent horizontal channels for randomly sampled committees (assigned at the beginning of each epoch).
Columns represent vertical channels for data availability sampling.
Each channel is responsible for sampling ALL blobs at that specific index.
¶ Publishing to the Network
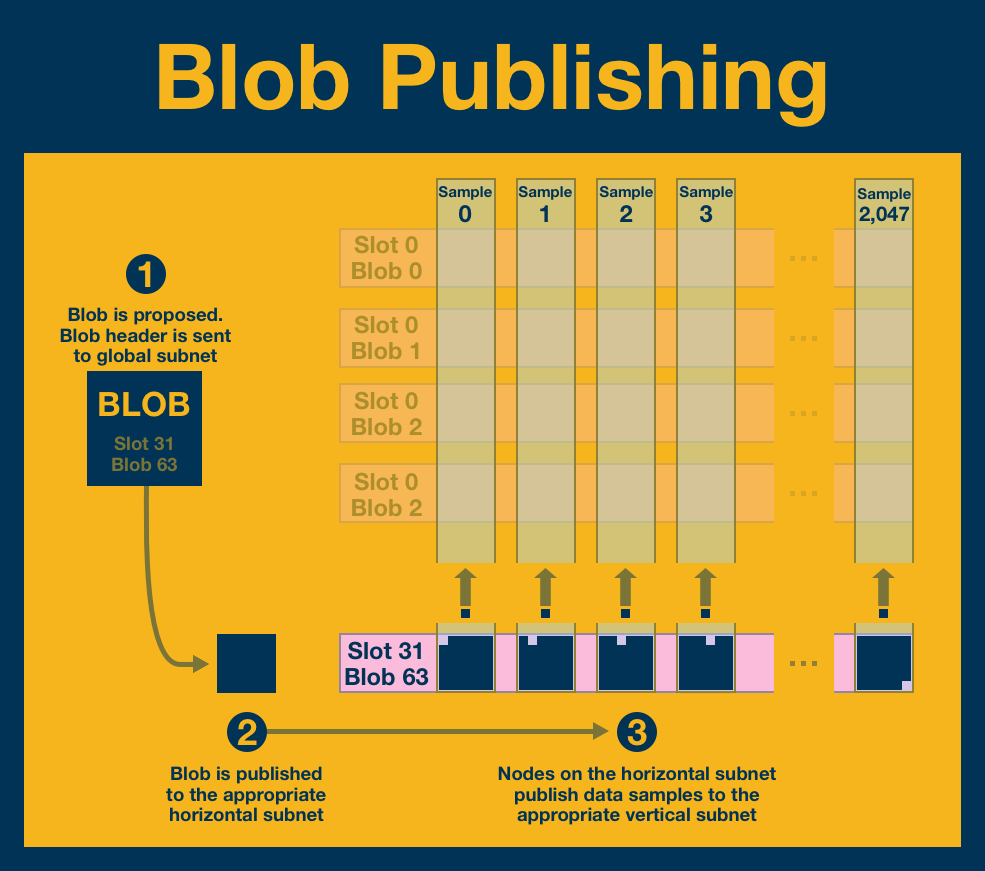
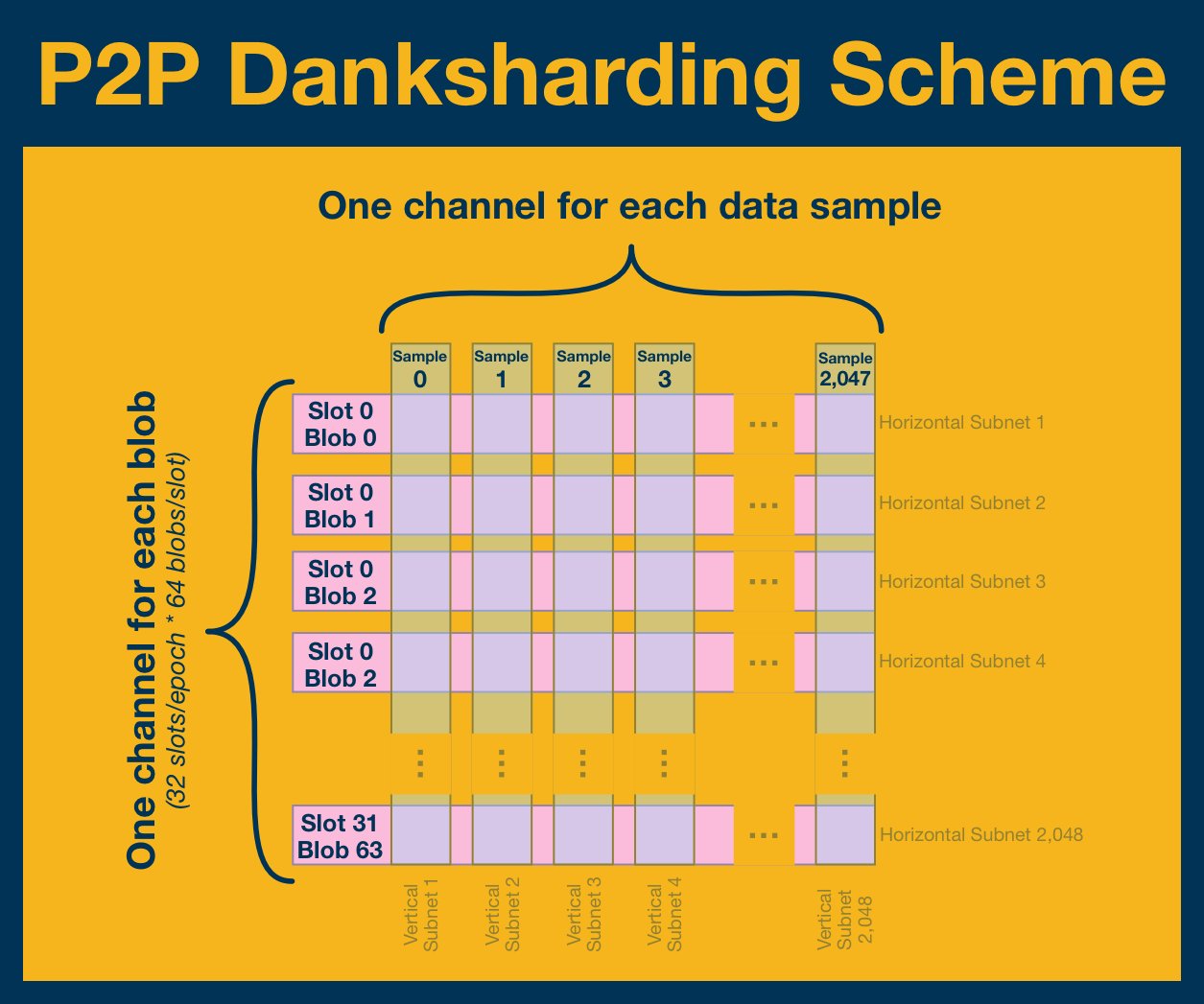
Publishing blobs to the network is a 3 step process:
- The blob proposer broadcasts the blob header to a global subnet.
- All nodes receive this header and use it for verification. The proposer broadcasts the blob to all peers on the appropriate horizontal subnet.
- As each node on the horizontal subnet receives a copy of the (full) blob, they identify the data samples corresponding to the vertical subnets they are subscribed to. They then isolate those samples and broadcast them to the appropriate vertical subnet.
¶ Data Implications
Let's add in some (realistic) numbers so you can get a sense of the idea.
In his blog, Vitalik talks about:
- ~20 data samples per node/validator
- 512 byte data sample size
- 1 MB blob size
And some basics, 1 epoch = 32 slots = 2,048 blobs
Let's imagine an entire epoch has passed under this system and consider the data implications.
- Each node is subscribed to a single horizontal subnet and so must download one blob.
- Each node is also subscribed to 20 vertical subnets and so must download 20 data samples.
1 blob (1 MB) + 20 samples (10 kB) = 1.1 MB of required data download/processing per epoch.
In contrast, if we made every blob download 100% of the data, each epoch would required 2,048 blobs (2 GB) and 0 samples.
We are talking about a 99.95% reduction.
BUT the result is that the data doesn't actually exist in its full form on the network. And so, before we can call our P2P design complete, we need to devise a way to recover the data.
We must reconstruct the blob using the pieces distributed around Ethereum.
¶ Retrieving from the Network
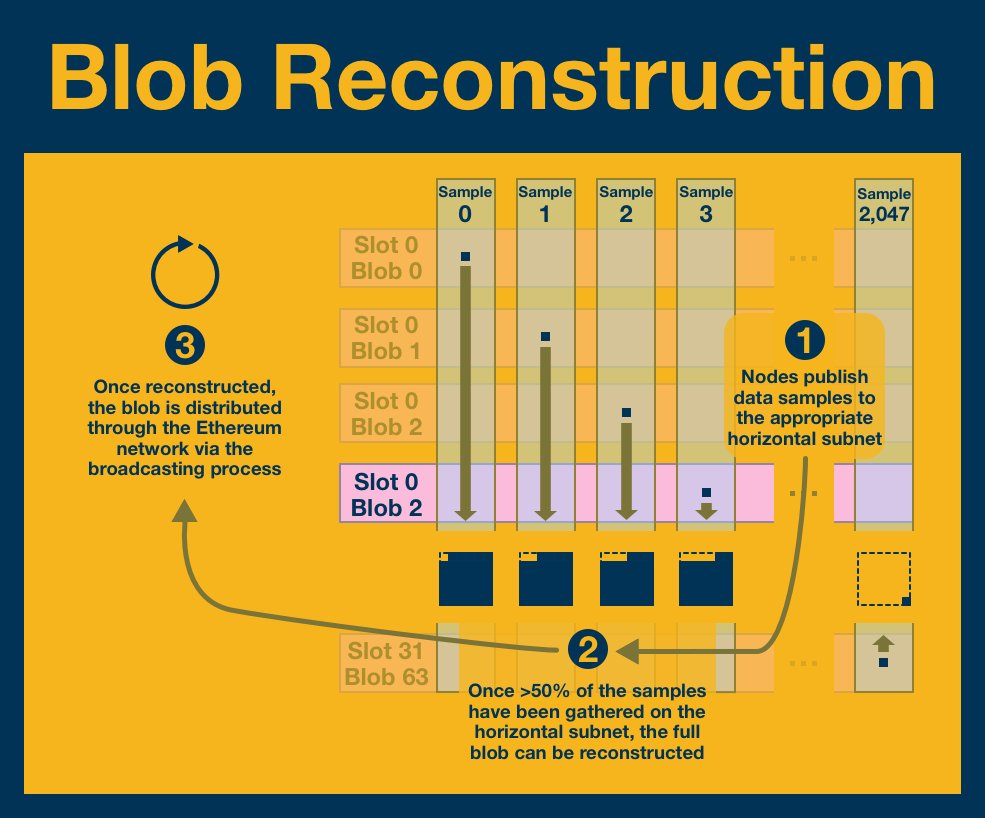
Fortunately, our design makes this process incredibly easy; we just run the publication process in reverse!
We begin with the vertical subnets. Each participant publishes the relevant sample to the appropriate horizontal subnet where it is reconstructed.
¶ Summary
This is the basic structure behind data scaling in Ethereum: we ensure all of the data is readily available within the system WITHOUT requiring any single node to hold it all.
The secret: clever P2P design that allows the efficient storage of movement and data.
But designing the network and creating a data-scheme is only half the battle.
The second half is actually designing the system.
For that, we are going to need something intricate... something secure enough to protect the World Computer.
Something super DANK!
¶ Resources
Source Material - Twitter Link
Source Material - PDF