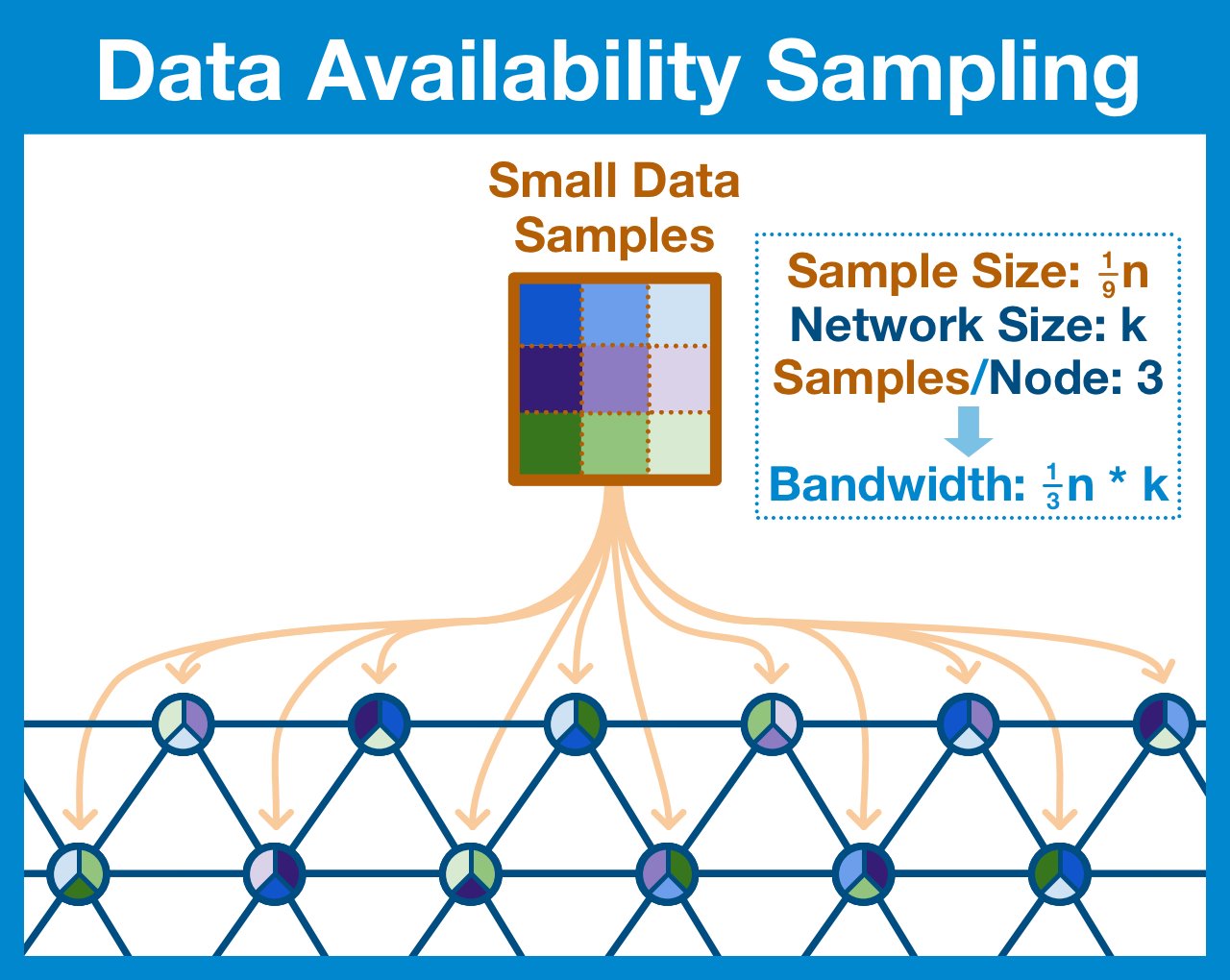
¶ Data Availability Sampling
¶ The World Computer
Ethereum exists between a network of 1,000s of computers (nodes), each running a local version of the Ethereum Virtual Machine (EVM). All copies of the EVM are kept perfectly in sync.
Any individual EVM is a window into the shared state of the World Computer.
Ethereum has been charting a course towards a rollup-centric future for ~2 years now.
Tl;dr Ethereum will scale by offloading execution to performance-optimized blockchains, while settlement and economic security will remain with mainnet.
¶ Data Availability
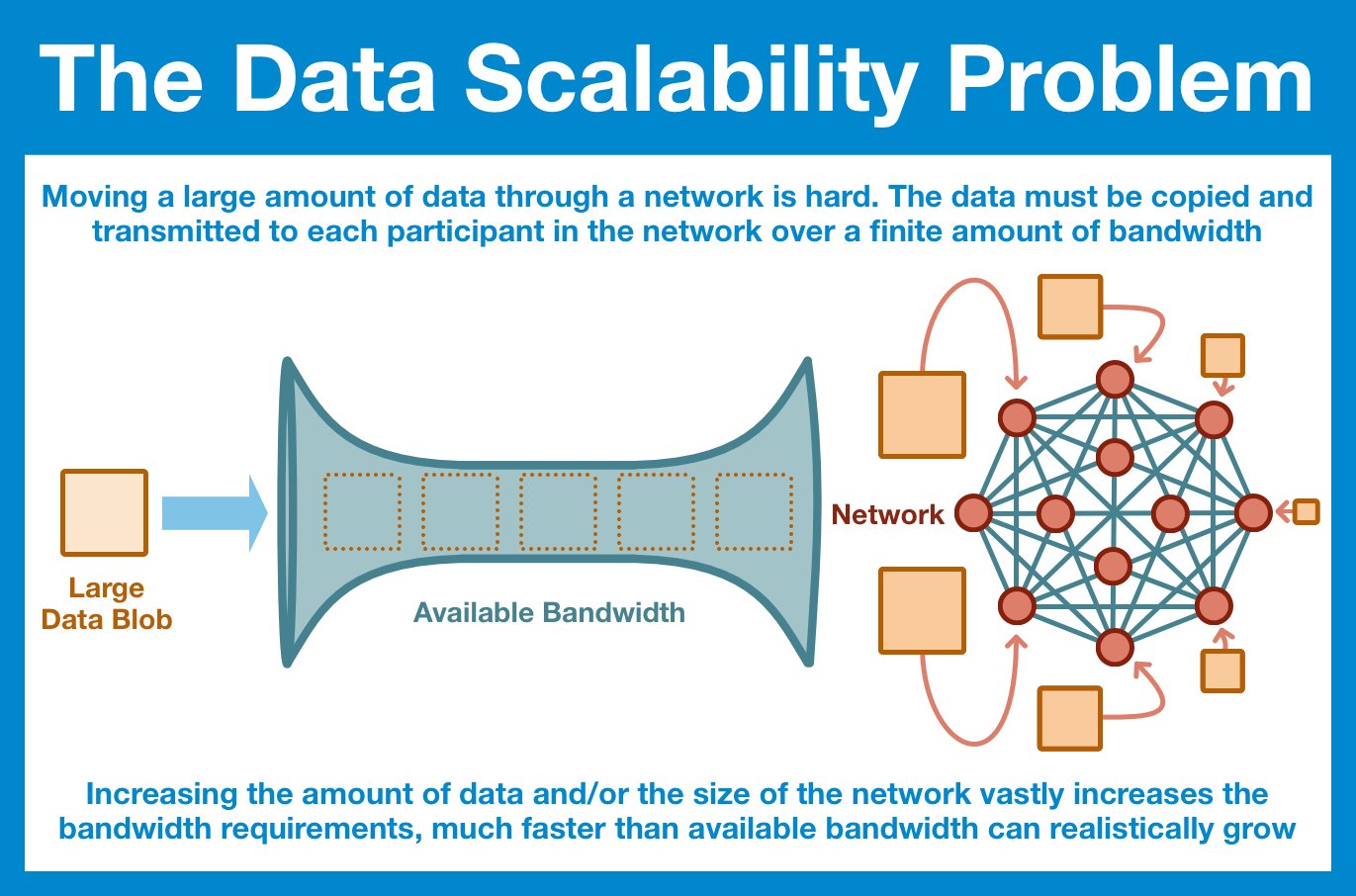
Deep Dive: Data Availability Scaling
The rollup-centric paradigm is based around quickly and cheaply executing transactions in a more centralized environment, and then posting a (compressed) record back to Ethereum.
In the rollup-centric future, it becomes critical to ensure that data is available.
Now look, I am an Ethereum zealot, a true believer in the inevitable dominance of the World Computer. I believe that billions and billions of transactions will happen on rollups every single day.
And that is A LOT of data circulate through the Ethereum network.
Before we continue we need to be clear on what kind of data we are talking about.
¶ Dealing with Rollup Data
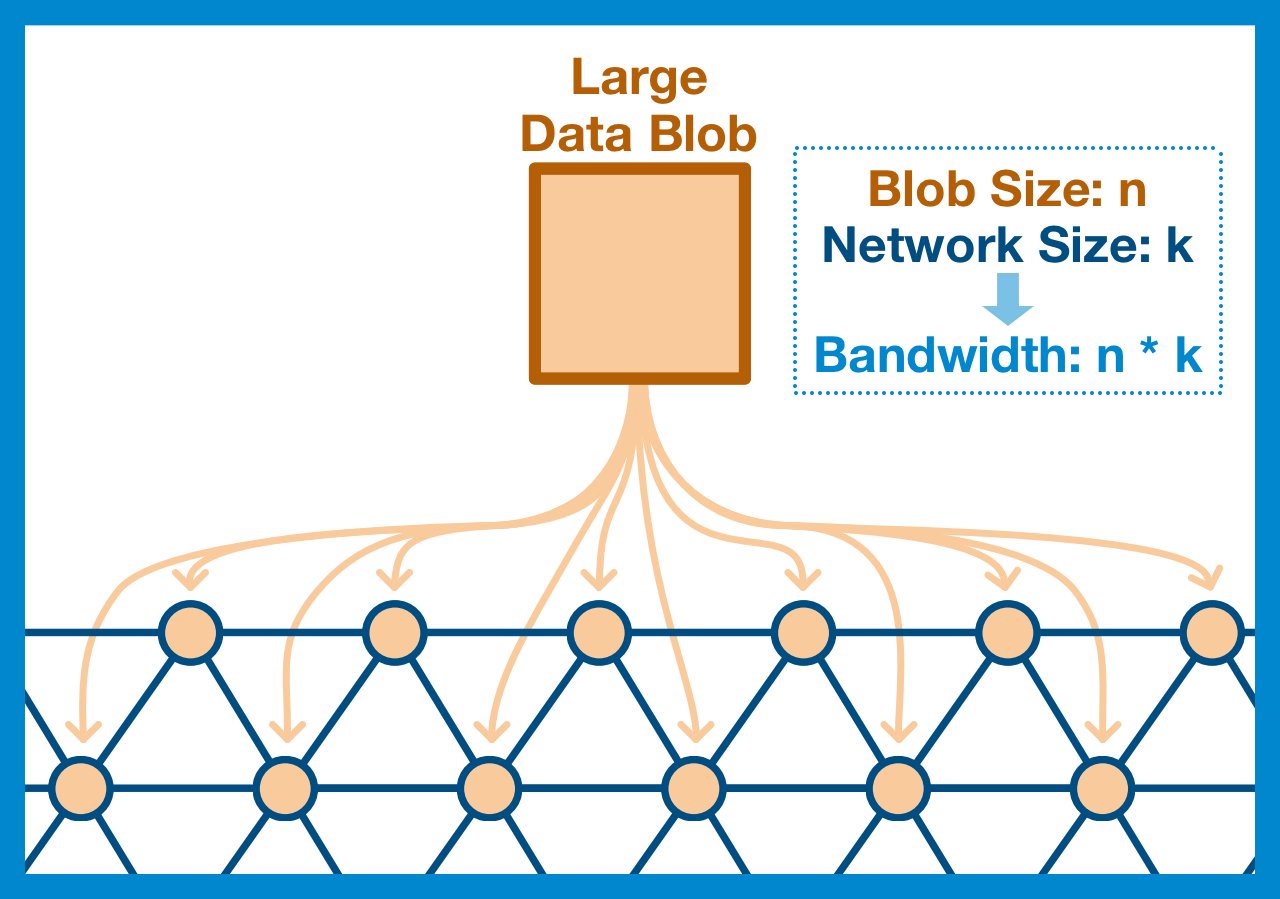
Any data within the EVM needs to be communicated across the entire network.
ALL nodes needs a copy of EVERY EVM state change.
Rollups exists OUTSIDE of the EVM; they are independent blockchains. Yes, they post a copy of the transaction to Ethereum but that's just to ensure immutability.
We only care that a copy is posted to the World Computer, not that each node gets a copy.
The most simple and obvious way to ensure that the data is posted to the World Computer is just to have every node in the network download it. Yes, the nodes don't NEED it, but at least we KNOW it's there.
But, as we've already discussed, this just isn't scalable.
Our goal is to guarantee that the entire blob was published to the network and is available for download... but there's no reason every node has to check the entire blob.
What if each node checked just some small random sample of the blob?
¶ Divide and Conquer
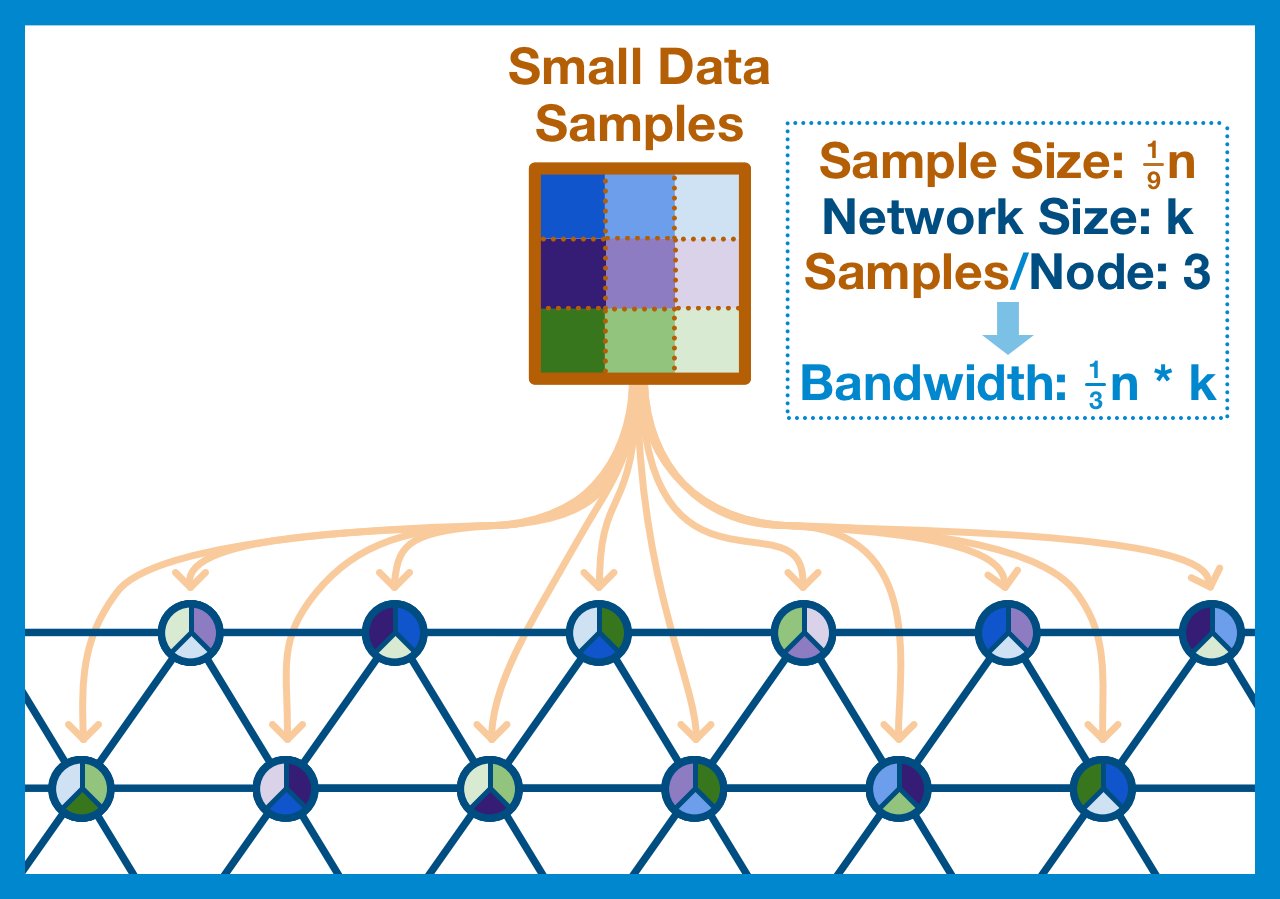
Yes, no single node will download the entire block, but if we are careful about how we break up our blob and ensure our sampling is random enough, we can be confident the entire block is available.
A good goal is for every node to verify that at least half of the blob's data is available. If less than half the data is available, then we can be confident that one of these samples will fail and the node will reject the blob.
¶ Importance of 100% Coverage
But what if only ONE sample is missing?
Let's say a blob is split into 100 samples, with each node randomly selecting 50. In this scenario, it is likely that a single invalid or unavailable sample might slip through.
We can't allow even a single transaction to skip verification; what if it mints 100 trillion USDC?
¶ Polynomial Erasure Codes
Deep Dive: Polynomial Erasure Codes
Fortunately, we have a simple solution: we are going to repackage our data. Instead of publishing the raw blob, we are going to apply a technology called erasure coding.
If a blob has been erasure encoded, the entire blob can be recovered with just 50% of the data.
Vitalik authored one of the better metaphors I've read for erasure coding, I'll just leave it here.

Bottom line: erasure code takes a message of length n and doubles it to 2n. But this added data comes with extra functionality: the ability to recover ALL 2n points.
¶ The Power of Erasure Coding
At first glance, this might not make too much sense. We are working with bandwidth issues and we just doubled the size of our blob...
But remember, we didn't just double it, we increased the size with these special new erasure codes.
Let's think this through.
First, the erasure codes change the game for an attacker; instead of hiding a single sample, an attacker would have to hide at least 50% of the blob. Otherwise, the network could just reconstruct the rest of the blob using the erasure codes.
Now, let's think about random sampling. Each choice is going to be completely random, there is no way for anyone (malicious or otherwise) to precompute which samples are going to be requested. So an attacker needs to hide >50% of the data, randomly selected.
Now combine these two concepts:
- an unavailable block needs to hide >50% of the data
- no entity can know which samples are going to be requested
Random sampling + erasure coding becomes incredibly (and efficiently) secure.
The example that Dankrad always gives is that if we query 30 random samples from an Ethereum block and all are available, the probability that less than 50% are available is 2-30 or .000000093%.
Our bandwidth problem looks WAY different at 30 samples than a full blob.
As Ethereum continues to build towards a rollup-centric future, it becomes critical to design for increased data requirements of a robust rollup ecosystem.
Data availability sampling is a huge step forward in ensuring data is available without crushing the network.
¶ Resources
Source Material - Twitter Link
Source Material - PDF