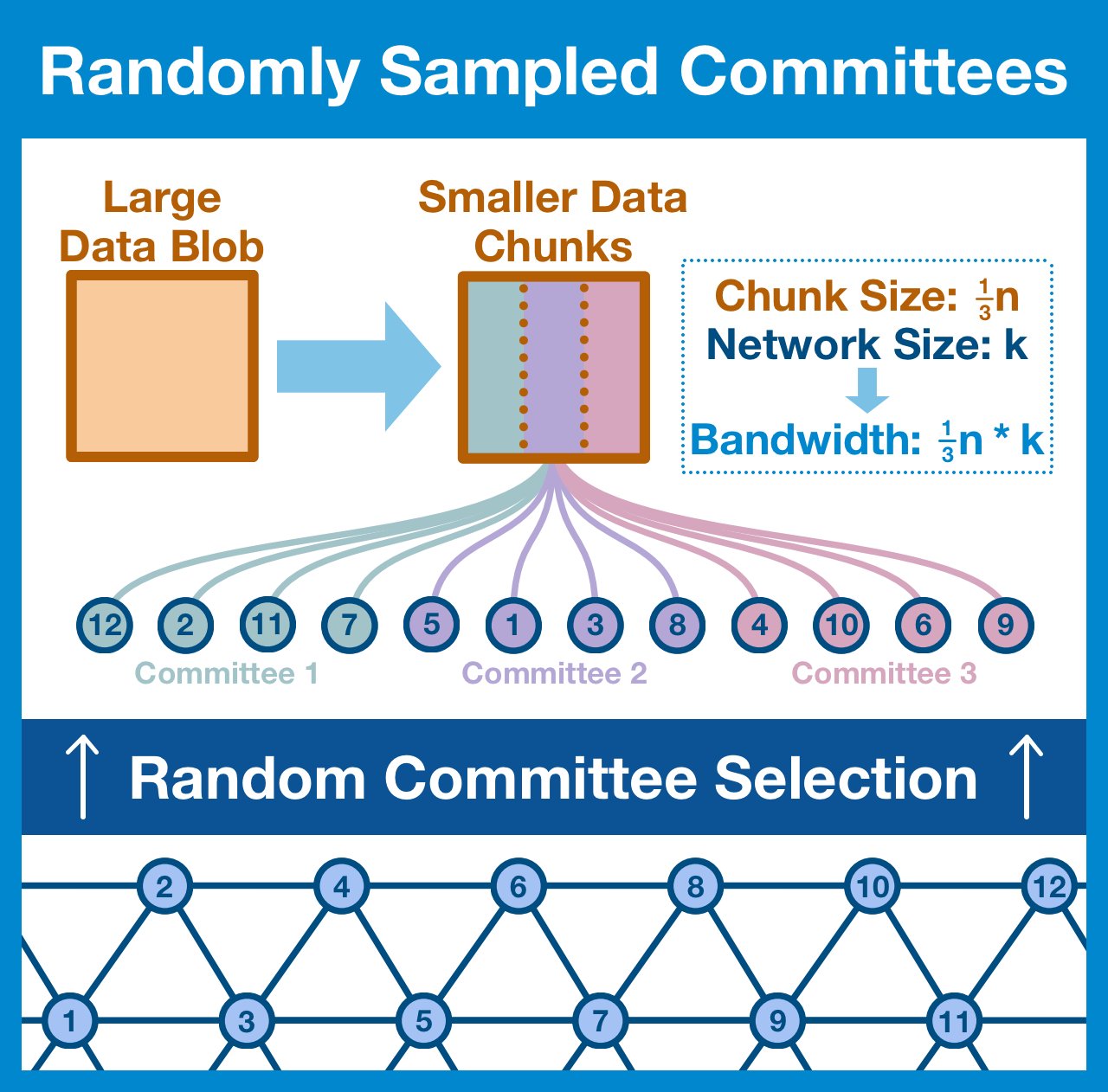
¶ Randomly Sampled Committees
¶ The World Computer
Ethereum exists between a network of 1,000s of computers (nodes), each running a local version of the Ethereum Virtual Machine (EVM). All copies of the EVM are kept perfectly in sync.
Any individual EVM is a window into the shared state of the World Computer.
Ethereum has been charting a course towards a rollup-centric future for ~2 years now.
Tl;dr Ethereum will scale by offloading execution to performance-optimized blockchains, while settlement and economic security will remain with mainnet.
¶ Data Availability
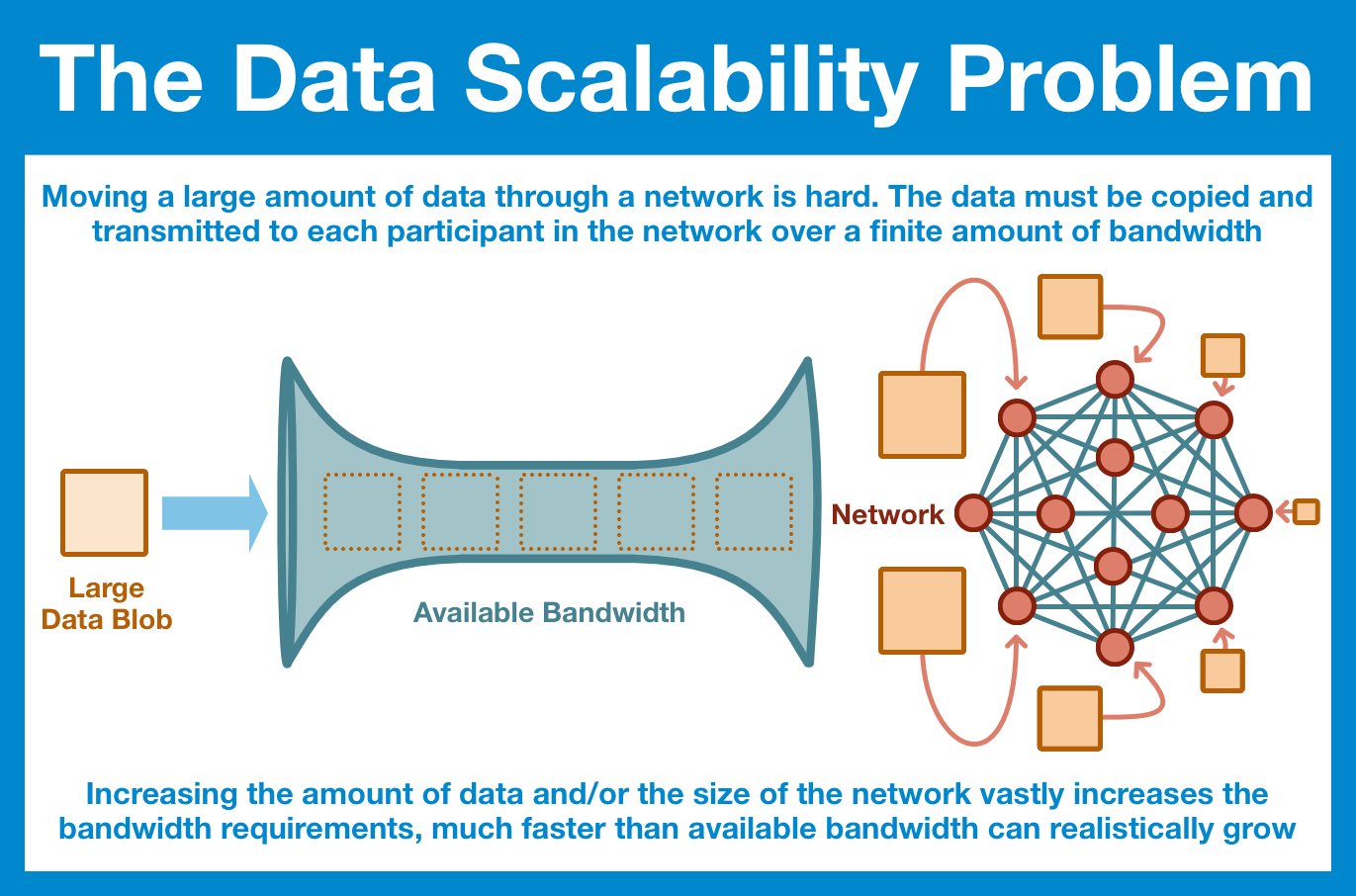
Deep Dive: Data Availability Scaling
The rollup-centric paradigm is based around quickly and cheaply executing transactions in a more centralized environment, and then posting a (compressed) record back to Ethereum.
In the rollup-centric future, it becomes critical to ensure that data is available.
Now look, I am an Ethereum zealot, a true believer in the inevitable dominance of the World Computer. I believe that billions and billions of transactions will happen on rollups every single day.
And that is A LOT of data circulate through the Ethereum network.
Before we continue we need to be clear on what kind of data we are talking about.
¶ Dealing with Rollup Data
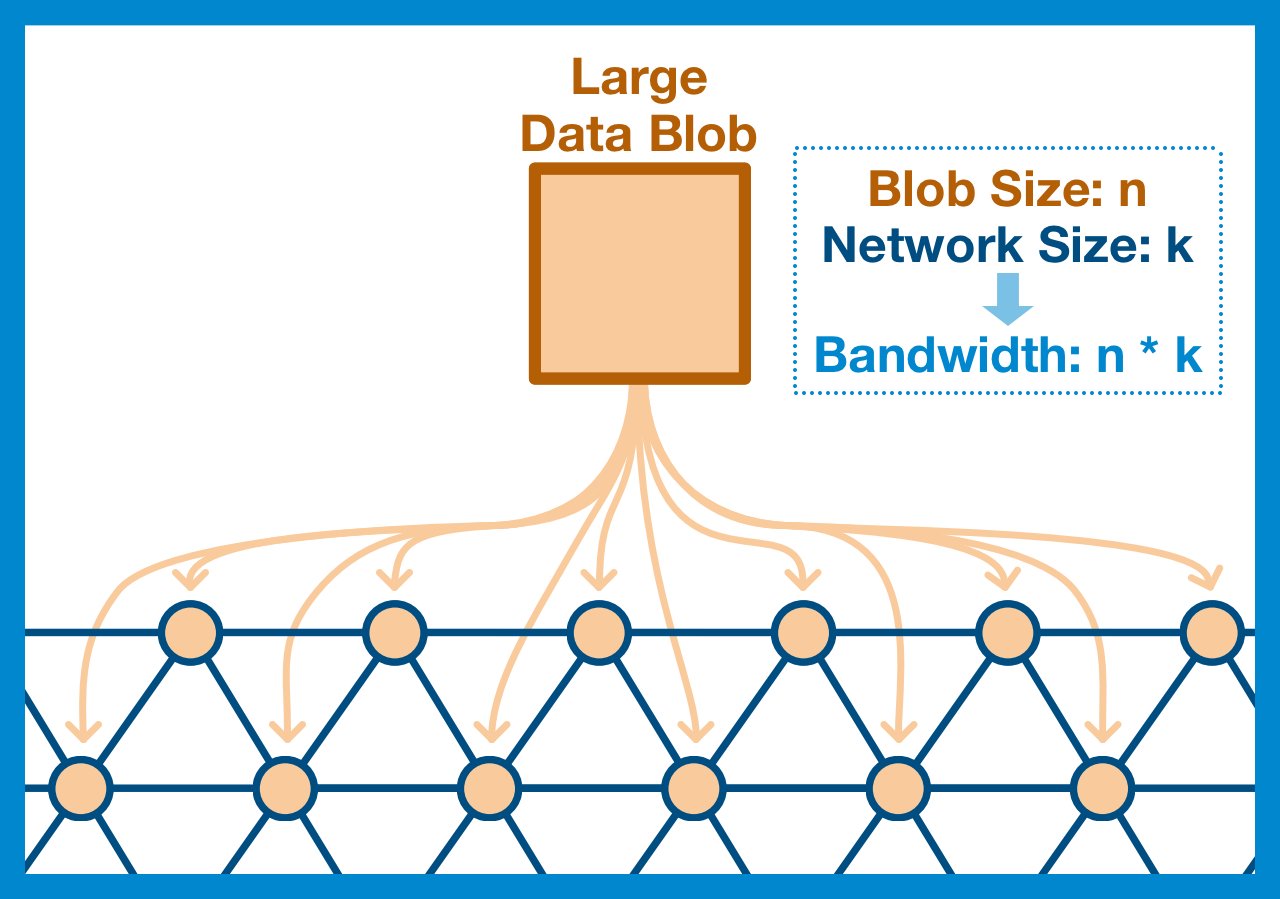
Any data within the EVM needs to be communicated across the entire network.
ALL nodes needs a copy of EVERY EVM state change.
Rollups exists OUTSIDE of the EVM; they are independent blockchains. Yes, they post a copy of the transaction to Ethereum but that's just to ensure immutability.
We only care that a copy is posted to the World Computer, not that each node gets a copy.
The most simple and obvious way to ensure that the data is posted to the World Computer is just to have every node in the network download it. Yes, the nodes don't NEED it, but at least we KNOW it's there. But, as we've already discussed, this just isn't scalable.
¶ Divide and Conquer
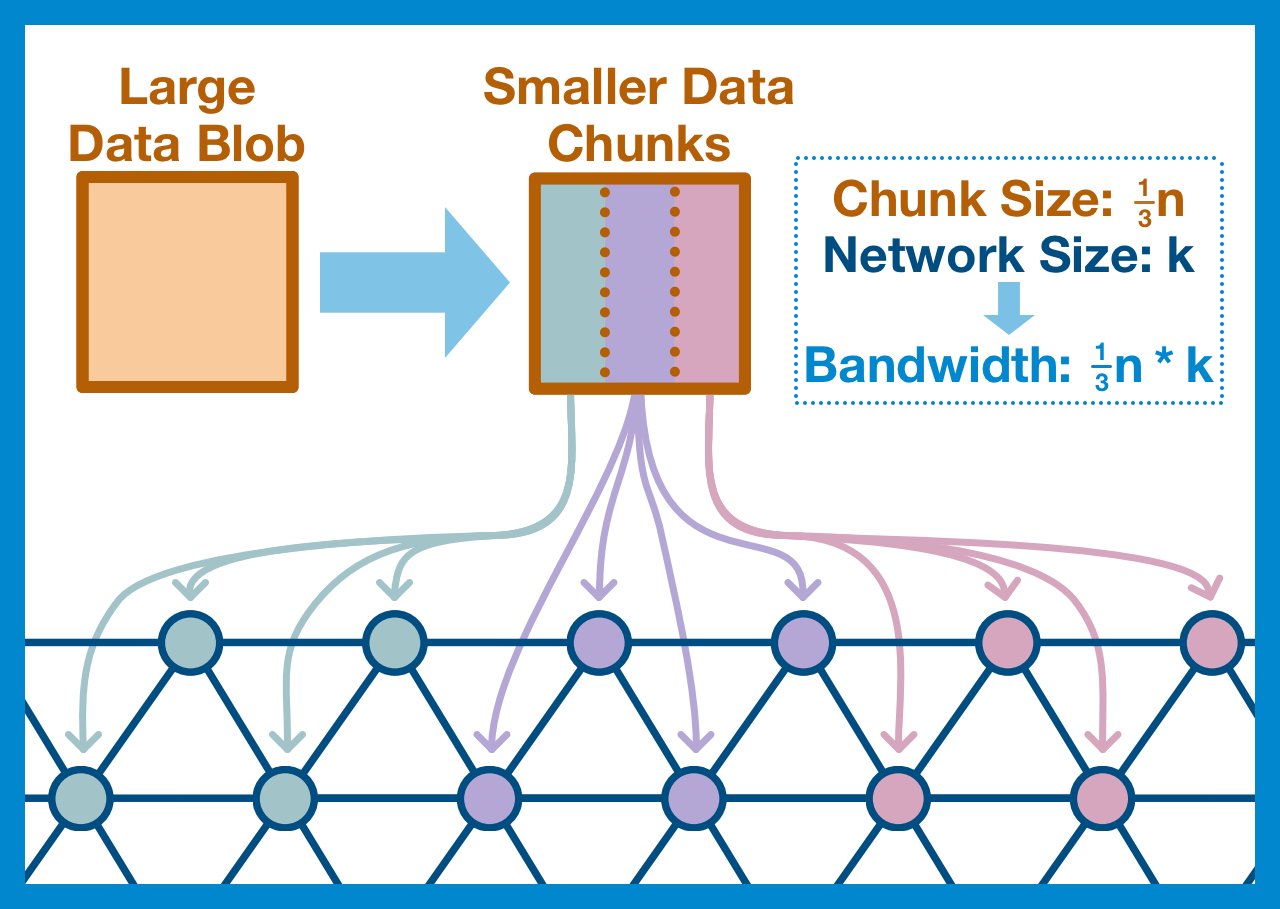
One idea is to split up the work: simply divide the nodes in your network and your data into an equal number of groups.
The nodes in group one can download and validate the first chunk, the nodes in group two can check the second, etc.
Each group (committee) is responsible for downloading their assigned chunk of data.
- If all/most of the committee can download it, the network can consider the chunk available.
- If all/most of the chunks are available, the network can consider the blob available.
¶ Example
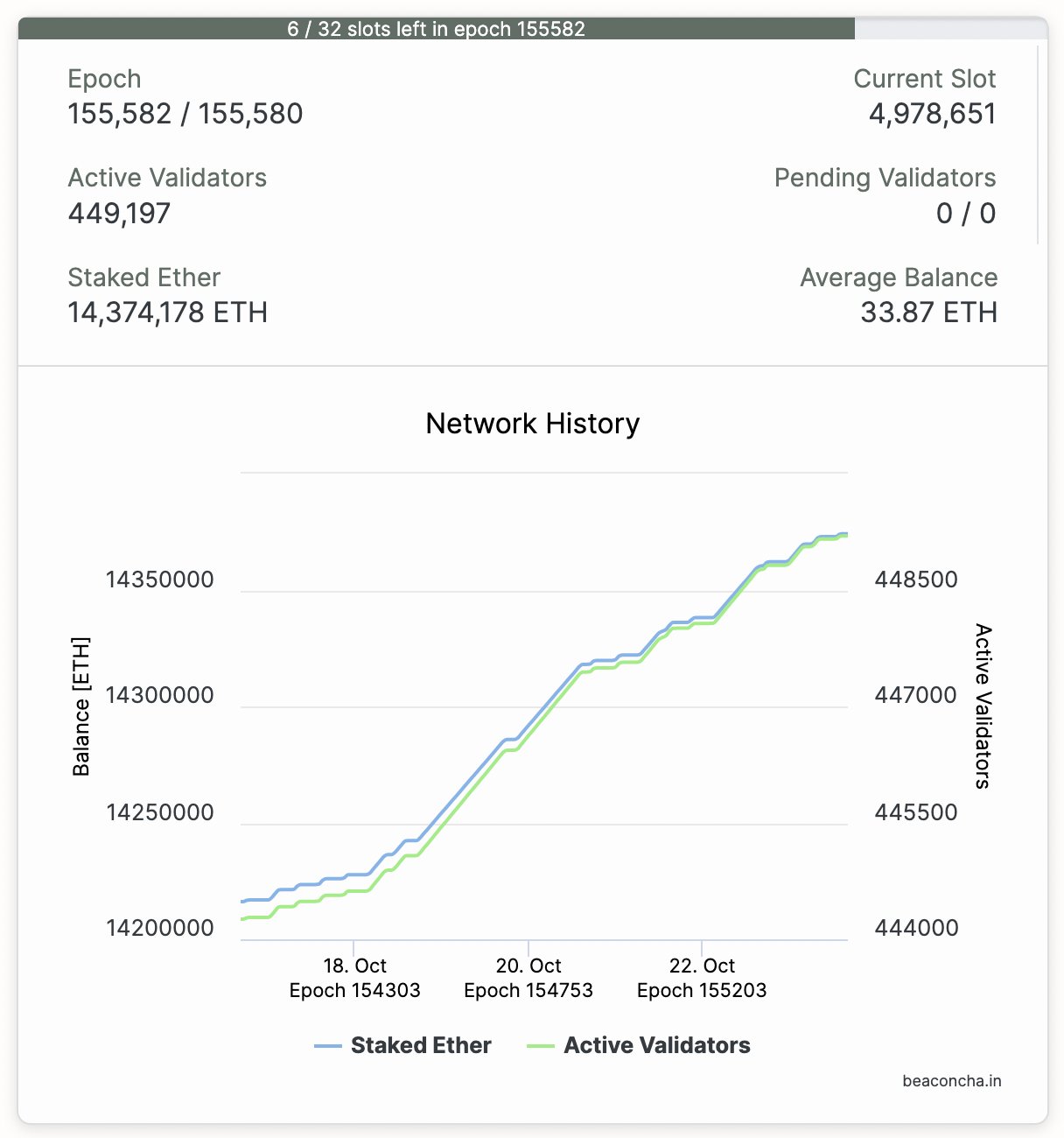
Go check out Beaconcha.in; you'll see there are currently ~450k Ethereum validators.
Let's decide that if 500 random validators can successful download a chunk of data, we can call it available. So let's just give ourselves committees of 1000, just in case.
450k validators / 1000 validators per group = 450 committees.
450 committees means we can split our data into 450 pieces, and therefore our bandwidth requirements are 450x less!
Change the parameters all you want, this committee approach will save a lot of bandwidth.
¶ Malicious Committees
But we have an issue.
Let's say a malicious node operator saved up his ETH until he had enough to deploy enough validators to control an entire committee.
With control of a committee, he could easily confirm an invalid or unavailable chunk.
In our example above, controlling .2% of the validators would give you 100% control over an entire committee. That committee would only have control over one chunk, but one chunk is enough.
What if it contains a transaction to mint 100,000,000,000 USDC?
¶ Shuffled Committees
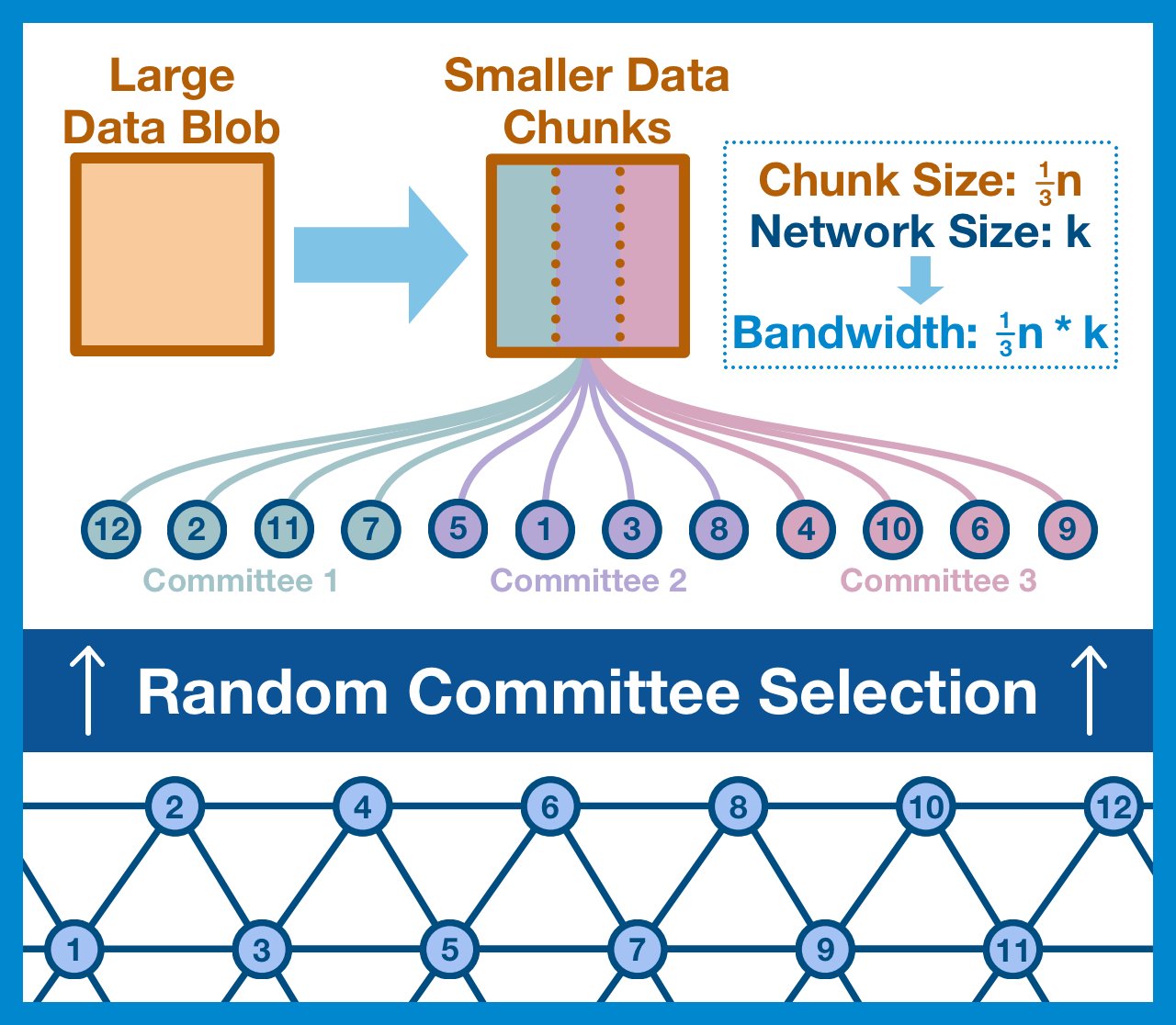
Fortunately, the solution is simple: we shuffle the validator set before we assign the data chunks.
Using a random seed, we assign each validator to a committee arbitrarily. A malicious node operator has no way to control which committees his validators are assigned to.
With enough validators, it's totally possible that an attacker might get lucky and gain temporary control over a single control over a committee. However, this situation is only mathematically realistic if they control >1/3 of all validators (compromising Ethereum PoS).
As Ethereum continues to build towards a rollup-centric future, it becomes critical to design for increased data requirements of a robust rollup ecosystem. Randomly sampled committees are a step forward in ensuring data is available without crushing the network.
¶ Resources
Source Material - Twitter Link
Source Material - PDF