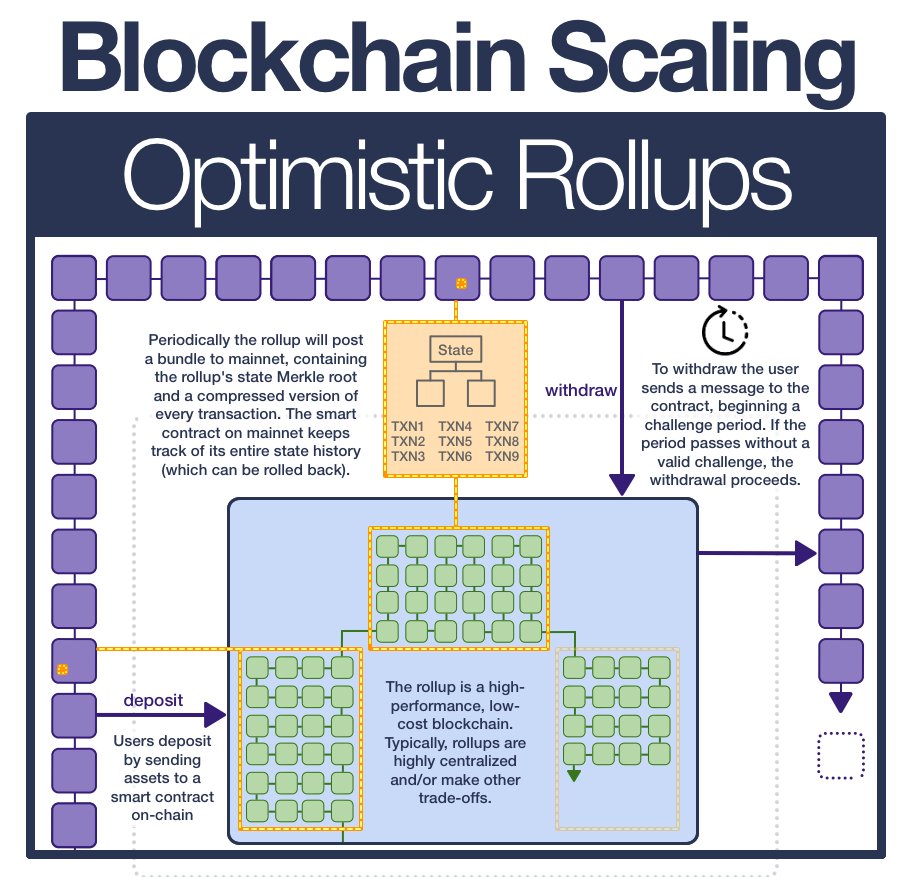
¶ Optimistic Rollups
¶ Prerequisites
¶ Merkle Tree
A Merkle Tree is a data structure used to organize and encrypt huge data sets.
Merkle Proofs can be used to efficiently verify that data exists in a dataset (confirmation a piece of data exists without transferring the whole dataset).
¶ Settlement
Settlement is the "final step in the transfer of ownership, involving the physical exchange of securities or payment".
After settlement, the obligations of all the parties have been discharged and the transaction is considered complete.
¶ The World Computer
In 2008, modern finance failed.
As Satoshi Nakamoto watched the world burn around him, he had a vision: Bitcoin.
7 years later, Vitalik Buterin delivered on the promise that Satoshi first gave us.
Ethereum was born.
Ethereum is the World Computer, a decentralized, globally shared utility. Unfortunately, the World Computer is slow...
...or at least it was born slow. Fortunately, we have scaling solutions!
¶ Early Scaling
¶ State Channels
The first group of scaling solutions are state channels.
To open a channel, the users fund a smart contract where the funds are held in on-chain-escrow. The participants can transact off-chain as much as they want.
When finished, the smart contract settles the channel.
State channels are powerful, but they have some serious limitations:
- participants must opt-in, cannot send funds to people who are not in channel
- requires large amount of capital to be locked
- cannot represent objects without a clear owner (eg Uniswap)
¶ Plasma
The next scaling solution was created to deal with (some of) these weaknesses.
Plasma (aka plasma chains) are independent blockchains that are anchored to Ethereum mainnet.
Just like Ethereum, a plasma chain has its own virtual machine state - the status/balance of every user & smart contract
This state can be represented as a Merkle tree - a data structure that allows a huge amount of data to be compressed into a single line (Merkle root).
Once every [interval] the plasma chain will build the state Merkle tree and post the Merkle root to mainnet. Thus, a (compressed) record of the entire plasma chain exists on mainnet.
In order to withdraw assets, a user submits the Merkle proof for that asset.
While plasma delivers improvement on state channels, they share a (huge) weakness: both require engaged ownership.
If an owner does not care about an asset, then an "invalid" outcome involving that asset may result. Good luck implementing a DEX... or really any dApp.
But there is an even bigger issue: data availability.
A plasma chain only posts the state Merkle root to mainnet; it does not post any of the transaction or block data needed to generate fraud proofs.
¶ Rollups
Rollups are the answer: post everything to mainnet.
¶ Deposit
Users interact with an optimistic rollup by depositing assets into a smart contract on Ethereum. The rollup operator then mints an equivalent amount of assets on the rollup chain and gives it to the depositor.
On mainnet, the assets remain in escrow.
¶ Execute

Because rollups rely on Ethereum for decentralized property rights and settlement, the rollup operator(s) can be much more centralized.
From a user perspective, execution times and gas costs are SIGNIFICANTLY cheaper than using mainnet.
Through here, rollups and plasma are basically the same thing. Both are high performance, centralized blockchains anchored to Ethereum via escrow smart contracts.
Plasma post the Merkle root to mainnet once every [interval], writing an unimpeachable record to mainnet. But plasma chains stop here; the only post the Merkle root to mainnet.
The Merkle root is a single line that can be used to prove a transaction.
You can only prove a transaction was in a Merkle tree, you cannot search the transactions in a Merkle tree just from its root.
During normal operation, this isn't an issue. Every time the plasma operator posts a new Merkle root, they also send every asset owner the necessary Merkle branches. Users must rely on the operator to provide block data if they need to create fraud proofs.
But what if one day they just... stopped.
A malicious operator could easily make an invalid transaction and hide the data necessary for creating the fraud-proof.
This wouldn't be possible if the operator was required to make transaction data available on mainnet.
¶ Publish
Rollups are the solution to plasma's data availability problems.
Putting ALL data on-chain allows anyone to locally process all the operations in the rollup if they wish to, allowing them to detect fraud, initiate withdrawals, or personally start producing transaction batches.
Operators publish a batch of transactions (including the previous and new state root) to the contract. The contract checks the submitted previous state root matches its copy of the current state root and, if so, switches the contract state root to the supplied state root.
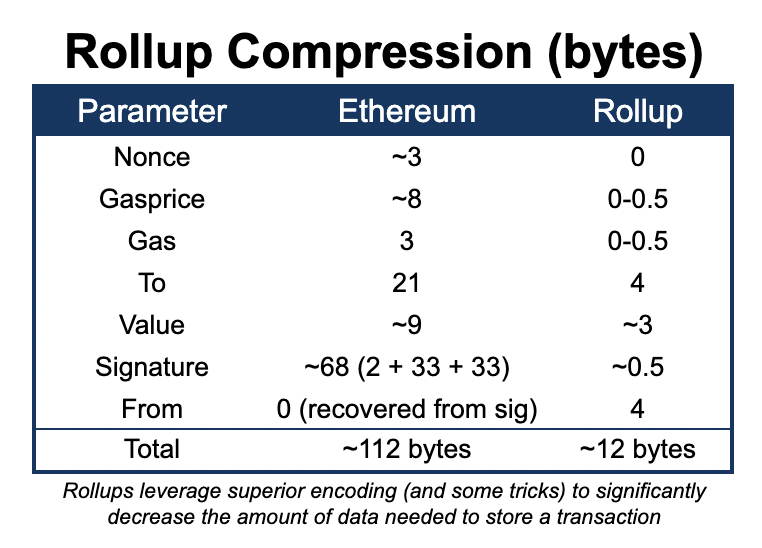
Rollups scale Ethereum in 2 ways:
- First, by moving computation to a high-performance chain, gas costs related to execution are drastically reduced
- Second, they are able to post transactions in a highly compressed form, greatly reducing the gas costs of posting data to mainnet
¶ Optimism
But there is one glaring issue: how does the smart contract know that the new state roots are correct?
An OPTIMISTIC rollup assumes all batches are valid... BUT it leaves open a challenge window.
Anyone who was keeping up with the chain and detects fraud can publish a fraud proof, proving the batch is invalid and should be reverted.
Thus, the rollup assumes good behavior, but relies on the economic incentives of untrusted actors to maintain its integrity.
¶ Withdraw
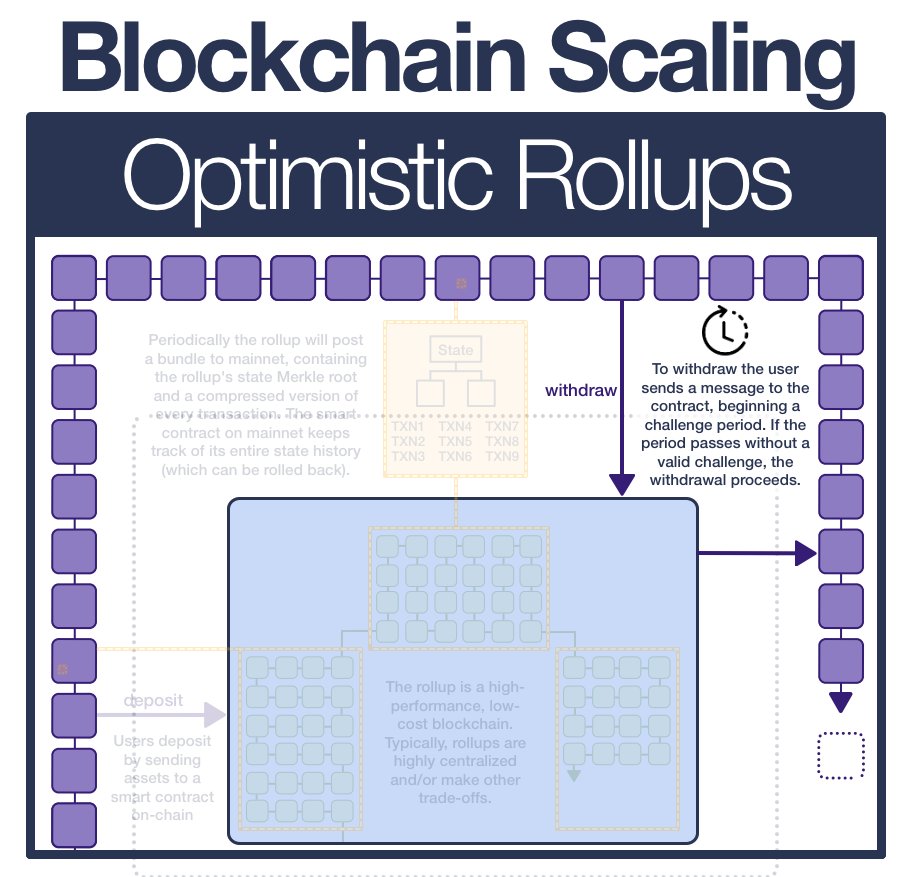
To withdraw, a user sends the contract a message and initiates a withdrawal transaction.
This changes the state of the rollup; a new batch/state root is posted on-chain. After the challenge window passes, the tranasction is finalized and the user can withdraw their assets.
¶ Summary
Both plasma and rollups are built on the same principle: offload execution while anchoring settlement to Ethereum.
But rollups make a huge leap forward by solving data availability.
The most important result: assets no longer needs owners.
Rollups can run an EVM.
A EVM-compatible/equivalent rollup is the dream: all the properties of Ethereum, just cheaper and faster.
...but we can do better, can't we? What if instead of being "optimistic" we wanted to settle things instantly?
Is verification possible with Zero-Knowledge?
¶ Resources
Source Material - Twitter Link
Source Material - PDF