¶ Stack
¶ Structured Data
Let's start with some data - let's just pick 30 random words from the BIP-39 list (the words used for your seed phrases).
Here's the 30 I picked, presented in two ways: unstructured (words are there, but that's it) and structured (aligned, alphabetical order).
Both representations hold the exact same set of data, but one is significantly easier to work with.
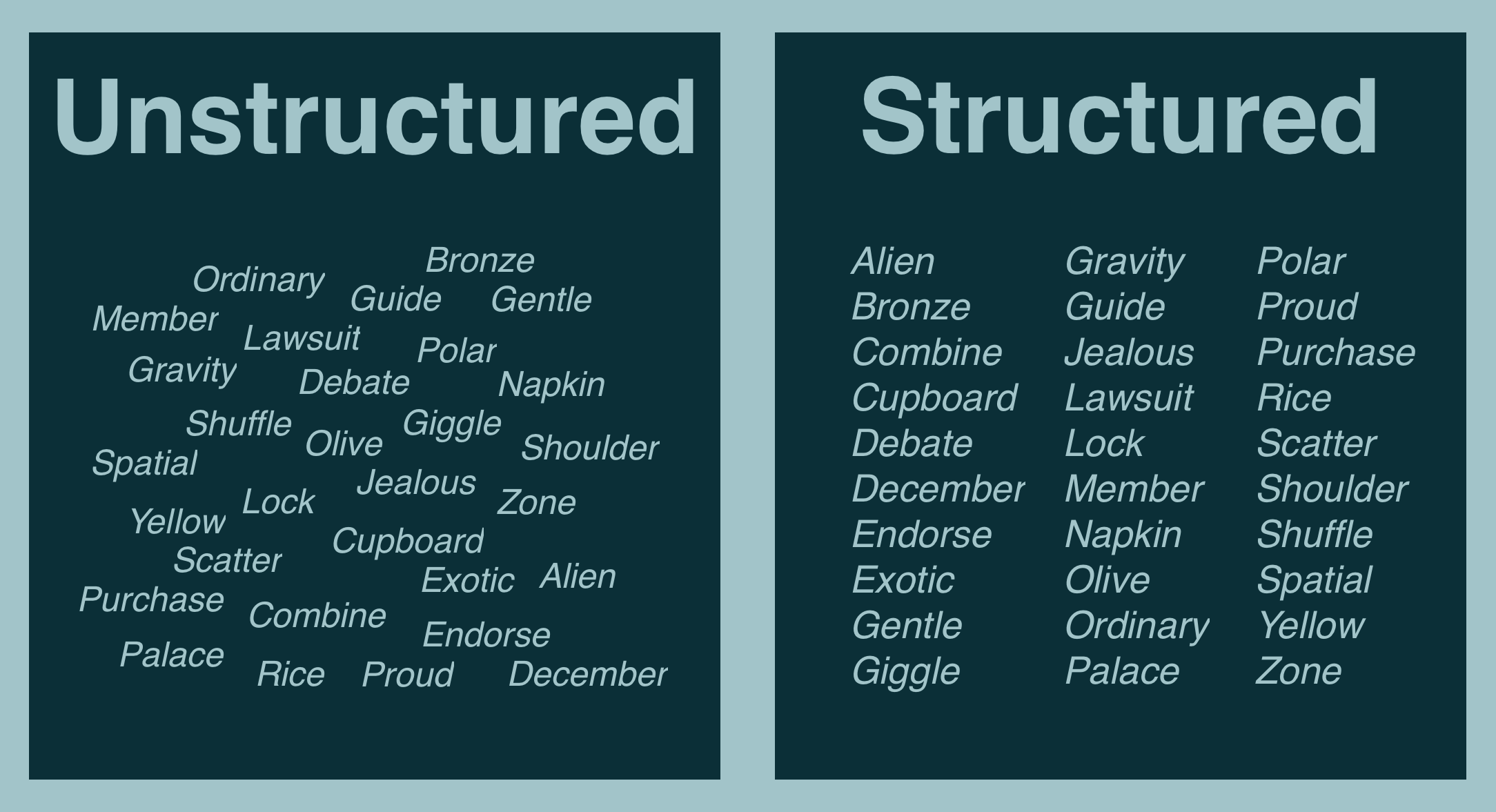
For example, let's say I ask you for "the only word that begins with J" or "all 4 letter words," it's much easier to determine the answer from the structured data.
Here we can see a core principle of computer science: organizing data efficiently is critical to making efficient algorithms (and therefore programs).
And so, a sub-field of study has emerged: the science of abstract data types (ADT), or, more commonly, data structures.
When you think of a data structure, you should think in two parts:
- the data contained within the data structure (the 30 words we chose)
- the container, relationships and functions that organize whatever data is put inside of it (aligned, alphabetical order).
There are many different data structures, each with their own benefits and limitations; it is up to the programmer to choose the data structure that works best for the problem want to solve.
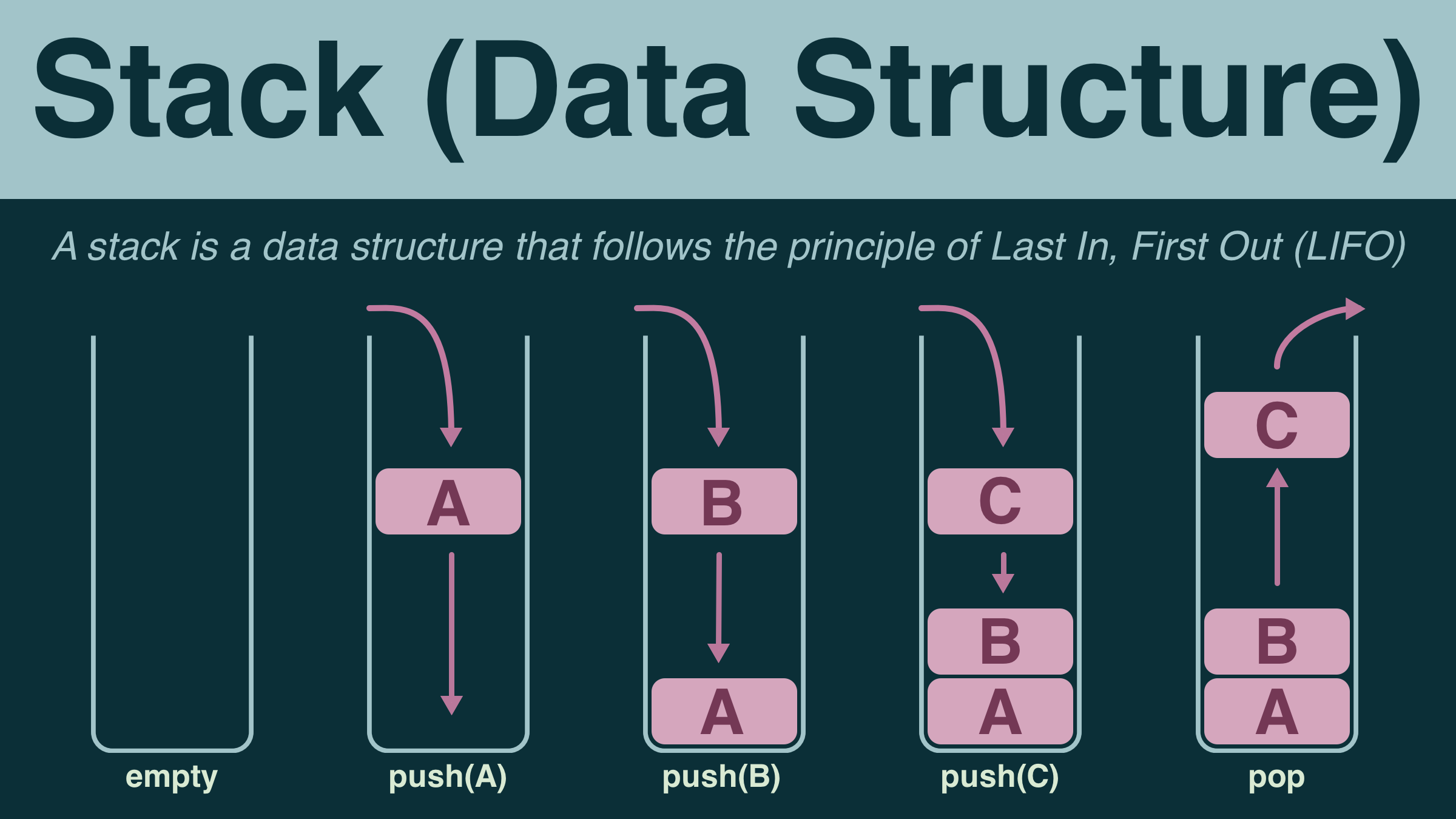
One of the most important data structures is called a stack.
¶ Stacks
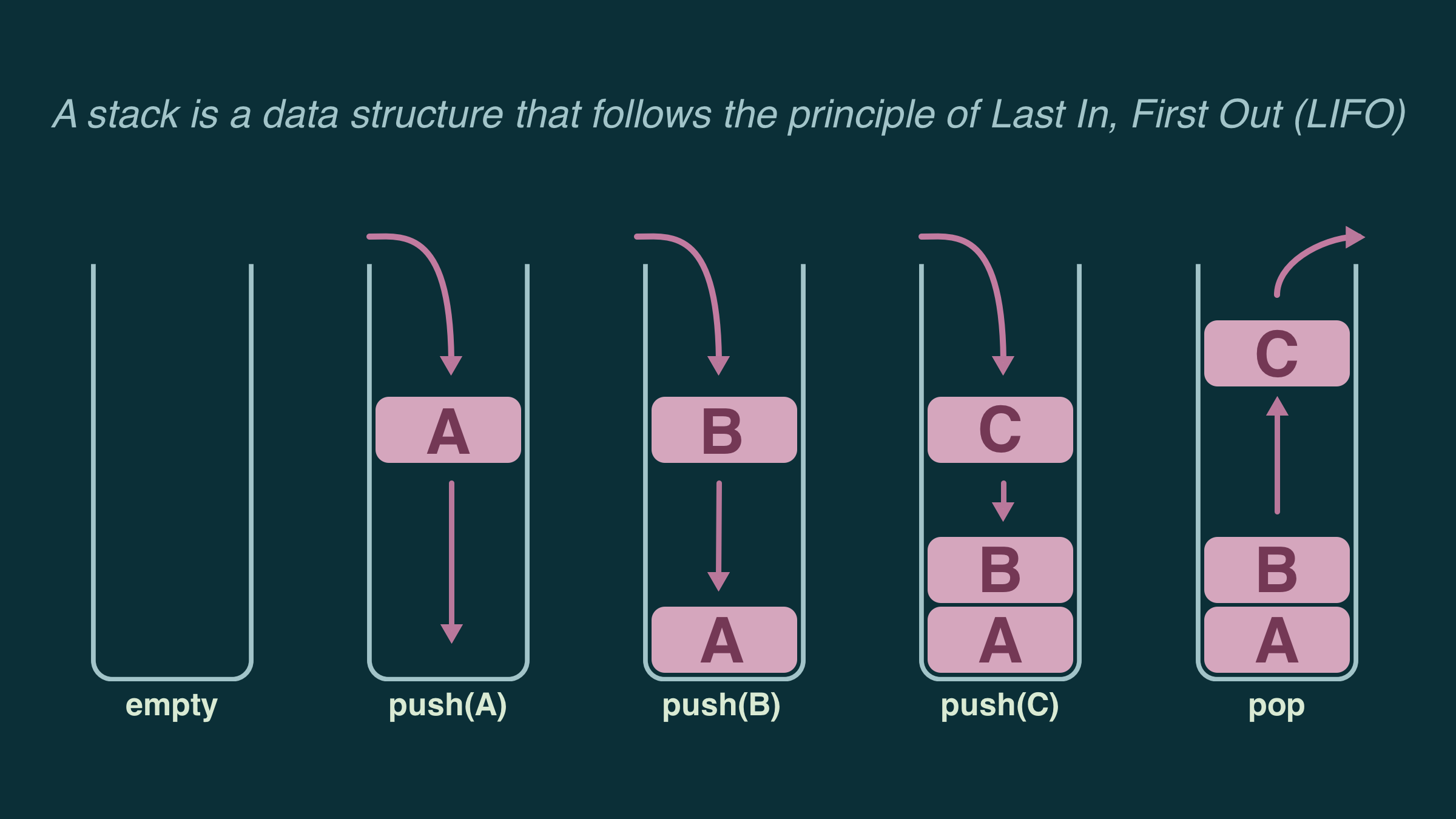
Like an array, a stack is an ordered list of elements (data). In an array, you access each element using its index (its position within that list).
A stack is different, it does not allow access to all of the elements - just the last one.
Think about a stack of plates, say 10 plates high, and you want to add an 11th. There's only one position for you to put your plate - on top.
Now the stack has 11 plates, and you need one. You can only grab the plate on the top - the last one placed on the stack.
A stack is a data structure that operates by the "Last In, First Out" (LIFO) principle. A stack has 3 (main) operations:
- push: add data to the stack
- pop: remove data from the stack
- peek: look at the data on the top of the stack (without removing it)
¶ Simply Optimized
As you can see, a stack is an incredibly lightweight (and inflexible) data structure. By giving up functionality (eg accessing arbitrary elements in an array), we make the stack as simple as possible.
And in computer science, simpler (often) means faster.
Let's return to arrays for a moment. The most important property of an array is that all the elements are stored next to each other.
When your computer wants to access data in the array, first it loads the beginning of the array, and then hops to the correct position.
With a stack, the computer doesn't need to worry about positioning at all; it just needs needs to keep track of the end of the stack.
Adding data? Look for the end of the stack and write new data. Need data? Look for the end of the stack and pull out the data.
In practice, the amount of overhead this saves on a single operation is negligible, but if you are working with enormous datasets with huge amounts of operations the savings add up.
In fact, this is more common than you might think...
¶ Stack Trivia
A stack plays a very important roll is (the vast majority) of all computer programs: it holds all the information about an actively running application.
There's no need to dive deep here, every high level computer language (like Python) will hide this from you.
Still, there is a particular reason it's worth knowing that a computer application stores all of its operational memory (think "scratch-space") in a stack...
...there is an entire classification of error for when your application accidentally jumps out of its stack.
In fact, you've probably heard of it: Stack Overflow!
(For the record, a stack underflow is when an application tries to access - peek/pop - a stack that is empty).
¶ Implementation
From a high level, that's everything you need to know about stacks. From here, it's time to look into arrays for the specific language you are working in.
Good Luck!
¶ Resources
Source Material - Twitter Link