¶ Arrays
¶ Structured Data
Let's start with some data - let's just pick 30 random words from the BIP-39 list (the words used for your seed phrases).
Here's the 30 I picked, presented in two ways: unstructured (words are there, but that's it) and structured (aligned, alphabetical order).
Both representations hold the exact same set of data, but one is significantly easier to work with.
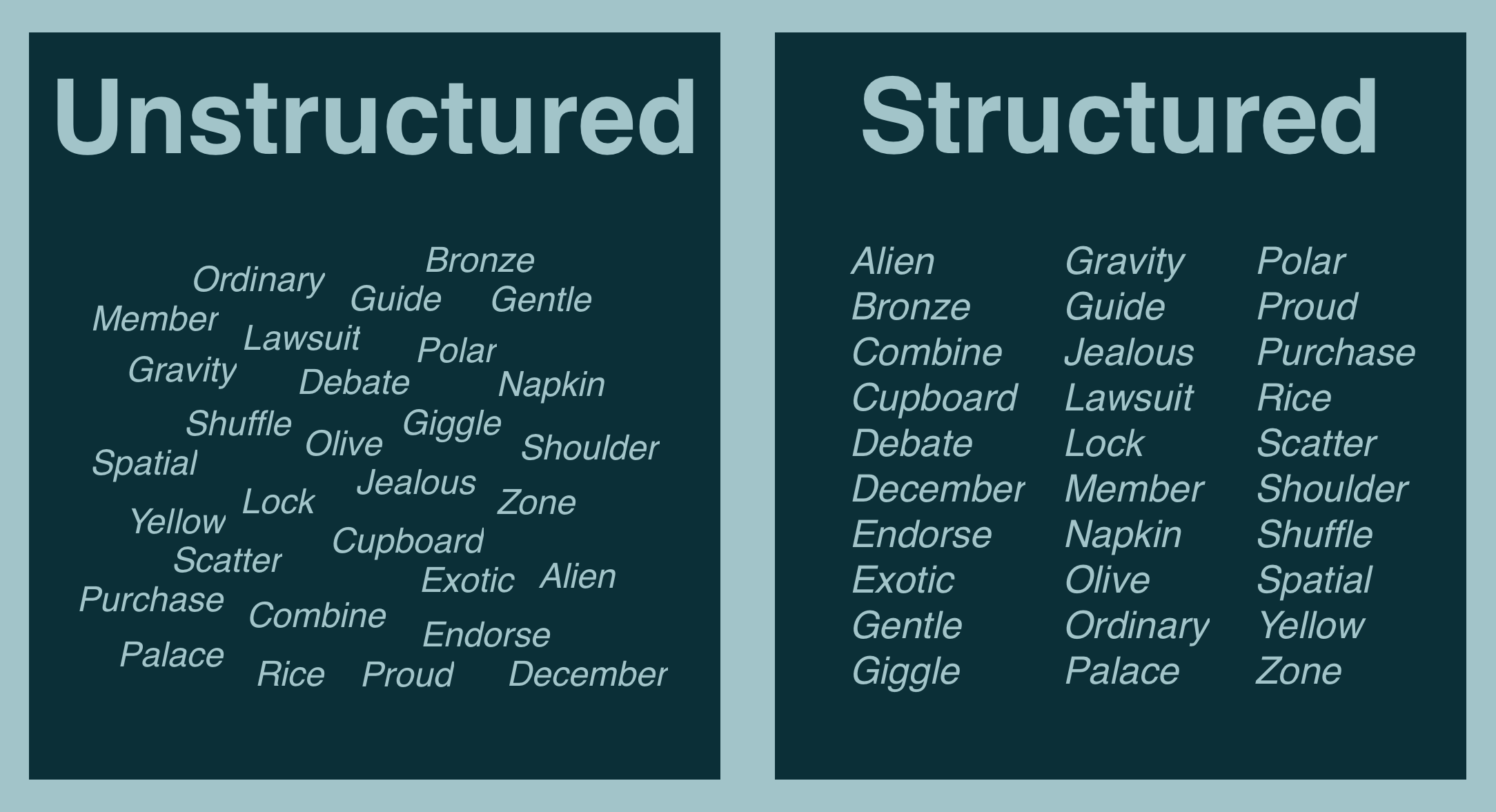
For example, let's say I ask you for "the only word that begins with J" or "all 4 letter words," it's much easier to determine the answer from the structured data.
Here we can see a core principle of computer science: organizing data efficiently is critical to making efficient algorithms (and therefore programs).
And so, a sub-field of study has emerged: the science of abstract data types (ADT), or, more commonly, data structures.
When you think of a data structure, you should think in two parts:
- the data contained within the data structure (the 30 words we chose)
- the container, relationships and functions that organize whatever data is put inside of it (aligned, alphabetical order).
There are many different data structures, each with their own benefits and limitations; it is up to the programmer to choose the data structure that works best for the problem want to solve.
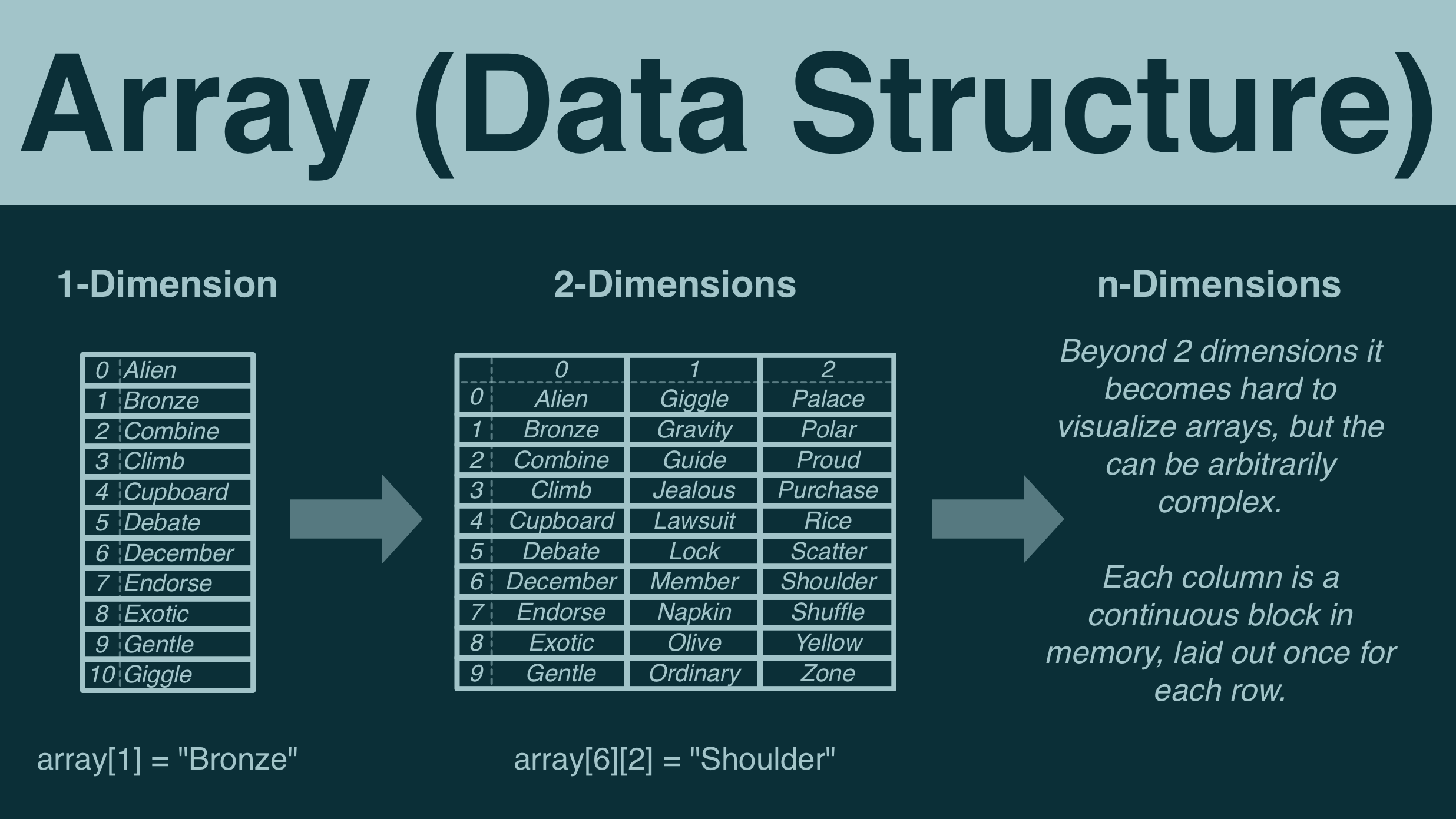
And so, let's dive in! First up, let's start with the basics: an array.
¶ Arrays
¶ Single Dimensional
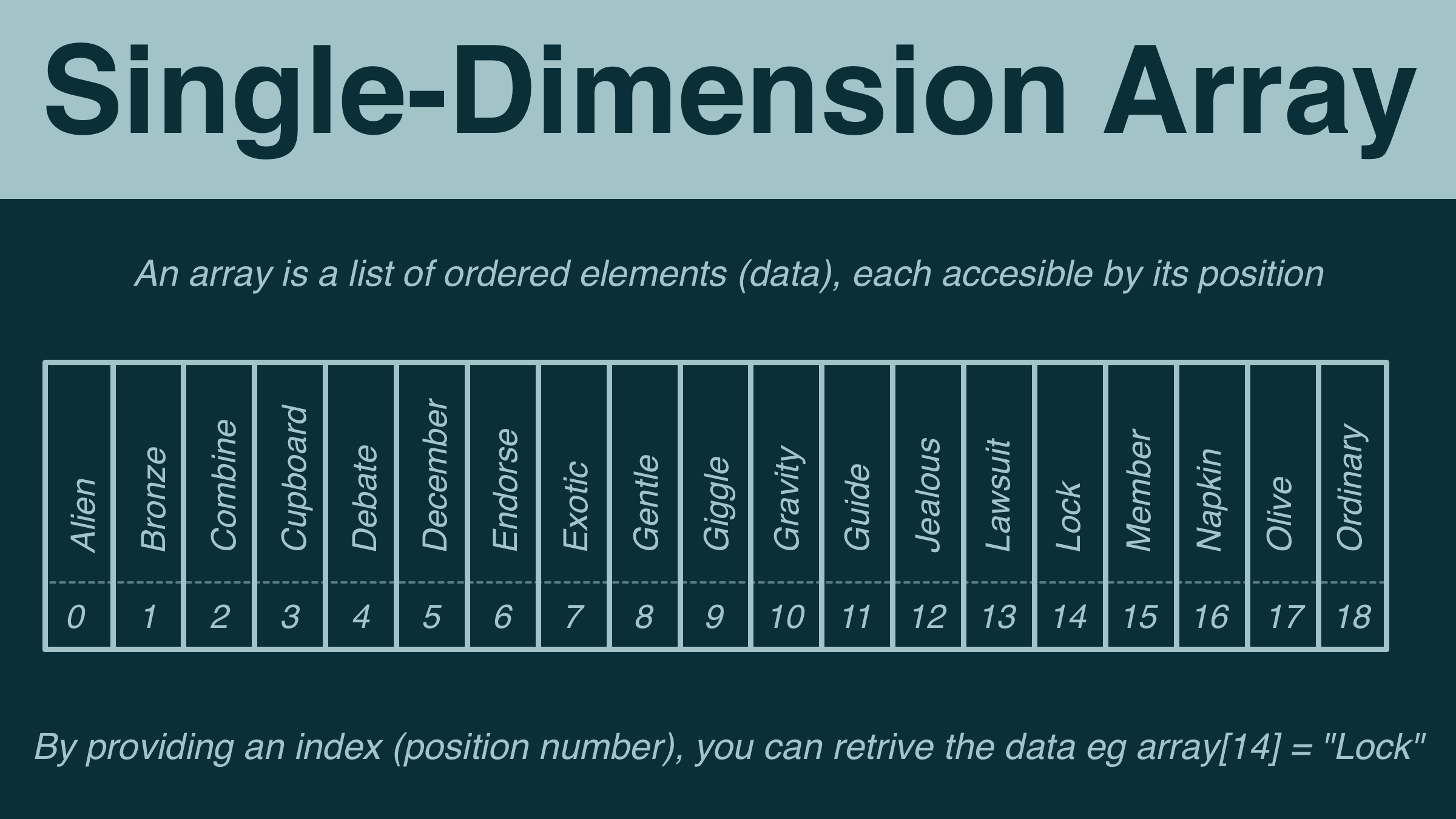
Let's say you are writing a program that needs to process 10 pieces of data (elements).
You could create a new variable that stores each individual piece of data, but then you'd need to keep track of 10 variables.
Or you could represent that same data as a single array.
An array is a data structure consisting of a collection of elements (data), each identified by at least one array index/key.
Each key directly corresponds with the position of its corresponding data element (eg the element in position 3 has key = 3).
The most basic kind of array is a single-dimensional array. Elements are listed in order and can be accessed using its position.
Most languages will use a notation like "array[14] = 'Lock'" to say "the element in position 14 is 'Lock'".
¶ Properties of Arrays
We wont go too deep, but its useful to understand some of the underlying properties of an array.
The most important thing to understand is that an array in always set up so that each element is adjacent to each other in memory.
This is in contrast to storing the data in individual variables. Each time you instantiate a new variable, the computer will just give you whatever section in memory is free at that particular moment.
Accessing each element requires accessing arbitrary areas in memory.
When data is stored in an array, the computer doesn't have to spend all this overhead retrieving data from across the entire memory space it has access to.
It reaches into memory one time to find the beginning of the array and then can quickly and easily hop around.
Beyond this, arrays have different properties depending on the specific programming language you are working in.
Things to consider: is the array structure immutable (can you change its length)? What is the index of the first element (usually arrays start with 0)?
¶ Multi-Dimensional Arrays
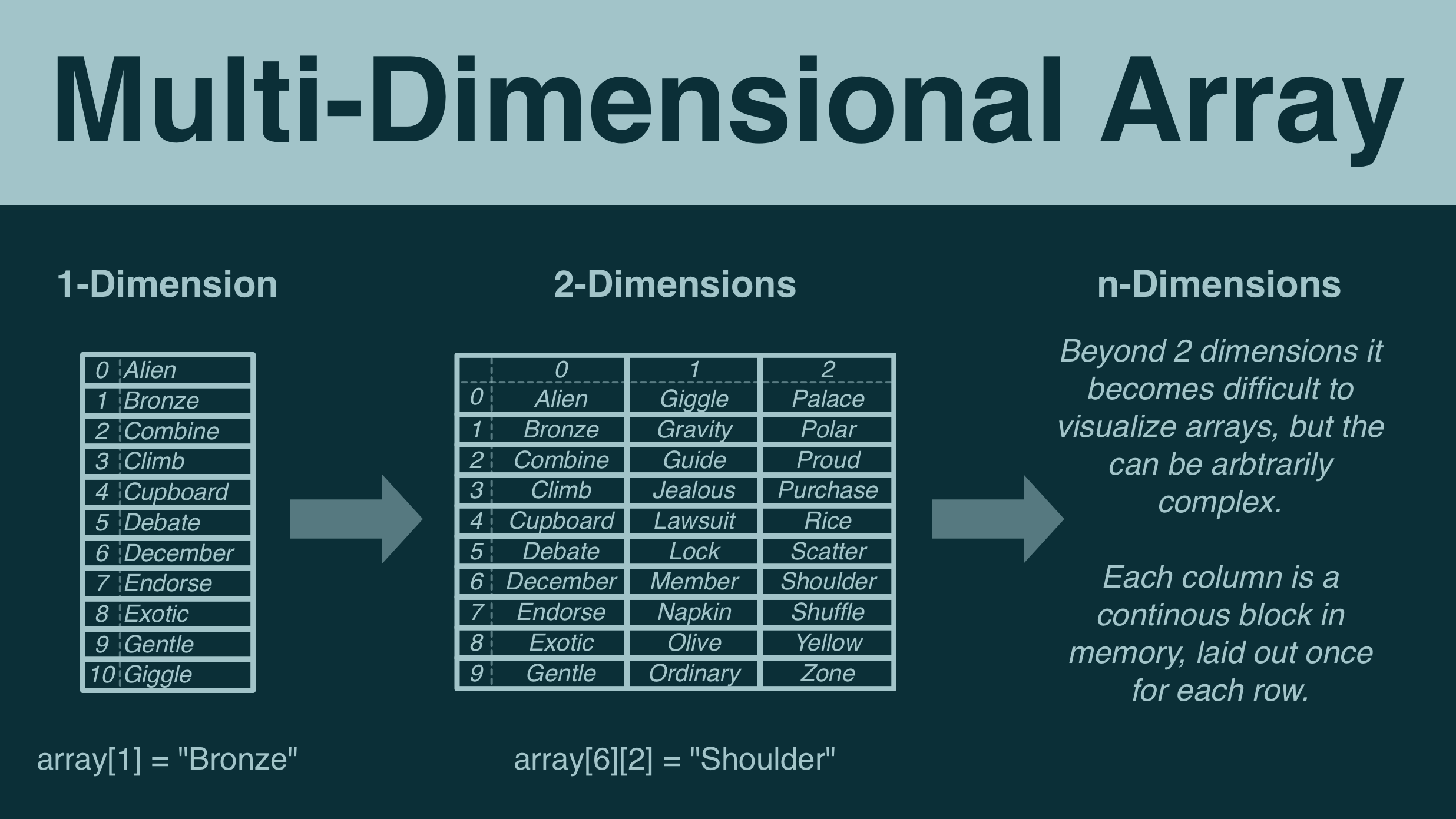
Let's return to the concept we just explored: that arrays lay out their elements contiguously in memory.
The easiest way to conceptualize this is as a list, which is useful on its own. But using a little trick, we can greatly extend this basic data structure.
While machines have no need for dimensions, they are a very useful human construct for our inferior minds.
If an array is a contiguous block in memory, and can be thought of as a list, then we can stack two of them side by side to create a table.
And so, arrays can be extended into an arbitrary amount of dimensions, providing incredibly efficient and organized access to arbitrarily complex dataset.
Most languages will use a notation like "array[8][1] = 'Olive'" to say "the element in row 8, column 2 is 'Olive'".
¶ Implementation
From a high level, that's everything you need to know about arrays. From here, it's time to look into arrays for the specific language you are working in.
Good Luck!
¶ Resources
Source Material - Twitter Link